

1. Introduction▲
Ce texte est un guide pratique pour l'Êcriture de votre propre système d'exploitation x86. Il est conçu de façon à fournir suffisamment d'aide à travers les dÊtails techniques et en même temps ne pas trop en rÊvÊler dans les Êchantillons et les extraits de code. Nous avons essayÊ de recueillir des parties de l'abondante (et souvent excellente) richesse de documents et de tutoriels disponibles sur le web et ailleurs, et d'ajouter nos idÊes personnelles sur les problèmes que nous avons rencontrÊs et dÝ rÊsoudre.
Ce livre ne traite pas de la thÊorie derrière les systèmes d'exploitation ni de la façon dont fonctionne un système d'exploitation (OS) particulier. Pour la thÊorie des OS, nous vous recommandons le livre Systèmes d'exploitation par Andrew Tanenbaum(1). Des listes et des dÊtails sur les systèmes d'exploitation actuels sont disponibles sur Internet.
Les premiers chapitres sont assez dĂŠtaillĂŠs et explicites, et vous amèneront rapidement Ă coder. Les chapitres suivants donnent plutĂ´t un aperçu de ce qui est nĂŠcessaire, au fur et Ă mesure que la mise en Ĺuvre et la conception relèvent plus du choix du lecteur, qui devrait maintenant ĂŞtre plus familier avec le domaine du dĂŠveloppement du noyau. Ă la fin de certains chapitres, il y a des liens pour des lectures complĂŠmentaires qui pourraient ĂŞtre intĂŠressantes et donner une comprĂŠhension plus approfondie des sujets abordĂŠs.
Dans les chapitres 2Outils et 3Passage au C, nous mettons en place notre environnement de dĂŠveloppement et dĂŠmarrons le noyau de notre OS dans une machine virtuelle, puis nous avons commencĂŠ Ă ĂŠcrire du code C. Nous continuons dans le chapitre 4Les sorties avec l'ĂŠcriture Ă l'ĂŠcran et sur le port sĂŠrie, puis nous plongeons dans la segmentation dans le chapitre 5Segmentation et dans les interruptions et la saisie de donnĂŠes en entrĂŠe dans le chapitre 6Interruptions et saisie.
Après cela, nous avons un noyau d'OS tout à fait fonctionnel, mais encore rudimentaire. Dans le chapitre 7La route vers le mode utilisateur, nous nous mettons en route vers les applications en mode utilisateur, avec une mÊmoire virtuelle à travers la pagination (chapitres 8Une courte introduction à la mÊmoire virtuelle et 9Pagination), l'allocation de mÊmoire (chapitre 10Allocation de trames de page), et enfin l'exÊcution d'une application utilisateur dans le chapitre 11Mode utilisateur.
Dans les trois derniers chapitres, nous discutons des sujets plus avancÊs concernant les systèmes de fichiers (chapitre 12Systèmes de fichiers), les appels système (chapitre 13Appels système) et le multitâche (chapitre 14Multitâche).
1-1. Au sujet de ce livre▲
Le noyau de l'OS et ce livre ont ÊtÊ produits dans le cadre d'un cours individuel avancÊ à l'Institut royal de technologie(2) de Stockholm. Les auteurs avaient dÊjà suivi des cours en thÊorie système, mais avaient une expÊrience pratique limitÊe dans le dÊveloppement du noyau du système d'exploitation. Afin d'obtenir une expÊrience personnelle plus dÊtaillÊe et une comprÊhension approfondie de la façon dont la thÊorie des prÊcÊdents cours système fonctionne dans la pratique, les auteurs ont dÊcidÊ de crÊer un nouveau cours, qui a portÊ sur le dÊveloppement d'un petit système d'exploitation. Un autre objectif du cours Êtait d'Êcrire un tutoriel complet sur la façon de dÊvelopper un petit OS à partir de zÊro, et ce petit livre en est le rÊsultat.
L'architecture x86 est depuis longtemps l'une des architectures matÊrielles les plus courantes. Ce ne fut pas un choix difficile que d'opter pour l'architecture x86, avec sa grande communautÊ, de nombreux documents de rÊfÊrence et des Êmulateurs matures, comme cible de l'OS. La documentation et l'information concernant les dÊtails du matÊriel avec lequel nous avons dÝ travailler ne furent pas toujours faciles à trouver ou à comprendre, en dÊpit (ou peut-être à cause) de l'âge vÊnÊrable de cette architecture.
Le système d'exploitation a ĂŠtĂŠ dĂŠveloppĂŠ en Ă peu près six semaines de travail Ă temps plein. La mise en Ĺuvre a ĂŠtĂŠ rĂŠalisĂŠe en plusieurs petites ĂŠtapes. Après chaque ĂŠtape, le système d'exploitation a ĂŠtĂŠ testĂŠ manuellement. En dĂŠveloppant de cette manière incrĂŠmentale et itĂŠrative, il est souvent plus facile de trouver tout ĂŠventuel bogue introduit, puisque seule une petite partie du code a changĂŠ depuis le dernier ĂŠtat stable connu du code. Nous encourageons le lecteur Ă travailler d'une manière similaire.
Pendant les six semaines de dÊveloppement, presque chaque ligne de code a ÊtÊ Êcrite par les auteurs ensemble (cette façon de travailler est parfois appelÊe programmation en binôme). Notre conviction est que nous avons rÊussi à Êviter un grand nombre de bogues grâce à ce style de dÊveloppement, mais cela est difficile à Êtablir scientifiquement.
1-2. Le lecteur▲
Le lecteur de ce livre doit être à l'aise avec UNIX/Linux, la programmation système, le langage C et les systèmes informatiques en gÊnÊral (comme la notation hexadÊcimale(3)). Ce livre pourrait être une façon de commencer l'apprentissage de ces choses, mais ce sera plus difficile, et le dÊveloppement d'un système d'exploitation est dÊjà difficile en soi. Les moteurs de recherche et autres tutoriels sont souvent utiles si vous êtes bloquÊ.
1-3. RĂŠfĂŠrences et remerciements▲
Nous tenons Ă remercier la communautĂŠ OSDev(4) pour leur superbe wiki et ses membres serviables, et James Malloy pour son excellent tutoriel de dĂŠveloppement du noyau(5). Nous aimerions ĂŠgalement remercier notre superviseur, TorbjĂśrn Granlund, pour ses questions pertinentes et les discussions intĂŠressantes.
La plus grande partie de la mise en forme CSS du livre est basĂŠe sur le travail de Scott Chacon pour le livre Pro Git, http://progit.org/.
1-4. Contributeurs▲
Nous sommes très reconnaissants pour les correctifs que les gens nous envoient. Les utilisateurs suivants ont tous contribuÊ à ce livre :
1-5. Modifications et corrections▲
Ce livre est hĂŠbergĂŠ sur Github - si vous avez des suggestions, des commentaires ou des corrections, forkez simplement le livre, rĂŠdigez vos changements et envoyez-nous une pull request. Nous serons heureux d'intĂŠgrer tout ce qui rend ce livre meilleur.
1-6. Problèmes et recherche d'aide▲
Si vous rencontrez des problèmes lors de la lecture du livre, veuillez vÊrifier les problèmes sur Github pour trouver de l'aide : https://github.com/littleosbook/littleosbook/issues.
1-7. Licence▲
Tout le contenu est sous licence Creative Commons Attribution Non Commercial Share Alike 3.0, http://creativecommons.org/licenses/by-nc-sa/3.0/us/. Les exemples de code sont dans le domaine public - utilisez-les comme vous voulez. Les rÊfÊrences à ce livre sont toujours reçues chaleureusement.
2. Premiers pas▲
DÊvelopper un système d'exploitation (OS) n'est pas une tâche facile et vous pourriez vous poser à plusieurs reprises au cours du projet la question  Comment puis-je même commencer à rÊsoudre ce problème ?  lorsque vous rencontrez de diffÊrents problèmes. Ce chapitre vous aidera à mettre en place votre environnement de dÊveloppement et à dÊmarrer un système d'exploitation très petit (et primitif).
2-1. Outils▲
2-1-1. Configuration rapide▲
Nous (les auteurs) avons utilisÊ Ubuntu(6) comme système d'exploitation pour dÊvelopper le système d'exploitation et l'exÊcuter à la fois physiquement et virtuellement (en utilisant la machine virtuelle VirtualBox(7)). Un moyen rapide de mettre tout en place et le rendre fonctionnel est d'utiliser la même configuration que nous, puisque nous savons que ces outils fonctionnent avec les Êchantillons de code fournis dans ce livre.
Une fois Ubuntu, installÊ sur une machine physique ou virtuelle, les paquetages suivants doivent être installÊs en utilisant apt-get :
sudo apt-get install build-essential nasm genisoimage bochs bochs-sdl2-1-2. Langages de programmation▲
Le système d'exploitation sera dÊveloppÊ en utilisant le langage de programmation C(8)(9) et le compilateur GCC(10). Nous utilisons le C parce que le dÊveloppement d'un OS nÊcessite un contrôle très prÊcis du code gÊnÊrÊ et l'accès direct à la mÊmoire. Il est possible d'utiliser d'autres langages offrant les mêmes caractÊristiques, mais ce livre ne couvrira que le C.
Le code fera usage d'un attribut de type, spĂŠcifique pour GCCÂ :
__attribute__((packed))Cet attribut permet de nous assurer que le compilateur utilise une disposition de mĂŠmoire pour une struct exactement comme nous le dĂŠfinissons dans le code. Ceci est expliquĂŠ plus en dĂŠtail dans le chapitre suivant.
En raison de cet attribut, les exemples de code pourraient s'avĂŠrer difficiles Ă compiler avec un compilateur C autre que le GCC.
Pour l'ĂŠcriture du code assembleur, nous avons choisi NASM(11) comme outil, car nous prĂŠfĂŠrons la syntaxe de NASM sur GNU Assembler.
Le shell Bash(12) sera utilisĂŠ comme langage de script au long du livre.
2-1-3. Système d'exploitation hĂ´te▲
Tous les exemples supposent que le code est compilÊ sur un système d'exploitation de type UNIX. Tous les exemples de code ont ÊtÊ compilÊs avec succès en utilisant les versions 11.04 et 11.10 d'Ubuntu.
2-1-4. Système de compilation▲
L'utilitaire make(13) a ĂŠtĂŠ utilisĂŠ pour la compilation des exemples de Makefile.
2-1-5. Machine virtuelle▲
Lors du dÊveloppement d'un système d'exploitation, il est très pratique de pouvoir exÊcuter votre code dans une machine virtuelle plutôt que sur un ordinateur physique, car le dÊmarrage de votre OS dans une machine virtuelle est beaucoup plus rapide que de transfÊrer votre OS sur un support physique, puis l'exÊcuter sur une machine physique. Bochs(14) est un Êmulateur pour les plateformes à architectures x86 (IA-32) qui est bien adaptÊ pour le dÊveloppement du système d'exploitation en raison de ses fonctions de dÊbogage. D'autres choix populaires sont QEMU(15) et VirtualBox. Ce livre utilise Bochs.
En utilisant une machine virtuelle, nous ne pouvons pas garantir que notre OS fonctionne sur du matÊriel rÊel, physique. L'environnement simulÊ par la machine virtuelle est conçu pour être très similaire à leurs homologues physiques et le système d'exploitation peut être testÊ sur une machine rÊelle juste en copiant l'exÊcutable sur un CD et en recherchant une machine appropriÊe.
2-2. Amorçage (boot)▲
L'amorçage ou sÊquence de boot d'un système d'exploitation consiste à transfÊrer le contrôle au long d'une chaÎne de petits programmes, chacun d'entre eux Êtant plus  puissant  que le prÊcÊdent, et dans laquelle le système d'exploitation est le dernier  programme  de la liste. La figure suivante donne un exemple de processus d'amorçage :
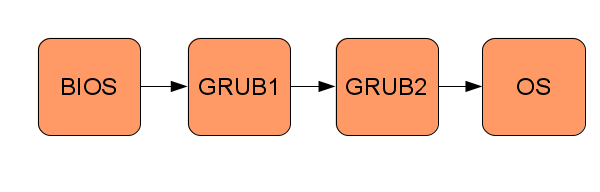
2-2-1. BIOS▲
Lors du dÊmarrage, l'ordinateur va lancer un petit programme qui adhère à la norme du Basic Input Output System ou BIOS(16), le système d'entrÊe-sortie de base. Ce programme est gÊnÊralement stockÊ sur une puce de mÊmoire en lecture seule sur la carte mère du PC. Le rôle initial des programmes BIOS Êtait d'exporter certaines fonctions de la bibliothèque pour l'impression à l'Êcran, la lecture de l'entrÊe au clavier, etc. Les systèmes d'exploitation modernes n'utilisent plus les fonctions du BIOS, ils utilisent des pilotes qui interagissent directement avec le matÊriel, en contournant le BIOS. Aujourd'hui, le BIOS exÊcute principalement des diagnostics prÊcoces (l'autotest à l'allumage), puis transfère le contrôle au chargeur d'amorçage.
2-2-2. Le chargeur d'amorçage (bootloader)▲
Le programme BIOS transfère ensuite le contrôle de l'ordinateur à un programme appelÊ chargeur d'amorçage (ou bootloader). La tâche de celui-ci est de transfÊrer le contrôle à nous, les dÊveloppeurs du système d'exploitation, et à notre code. Toutefois, compte tenu de certaines restrictions * du matÊriel et aussi pour des raisons de compatibilitÊ descendante, le chargeur d'amorçage est souvent divisÊ en deux parties : la première partie transfère le contrôle à la seconde partie, qui donne enfin le contrôle du PC au système d'exploitation.
L'Êcriture d'un chargeur d'amorçage consiste à Êcrire beaucoup de code de bas niveau qui interagit avec le BIOS. Par consÊquent, nous allons utiliser un chargeur d'amorçage existant : le chargeur d'amorçage GRand Unified Bootloader (GRUB)(17) du GNU.
En utilisant le GRUB, le système d'exploitation peut être compilÊ comme un exÊcutable ELF (Executable and Linkable Format - format exÊcutable et liable) ordinaire(18), qui sera chargÊ par le GRUB à l'emplacement mÊmoire appropriÊ. La compilation du noyau exige que le code soit disposÊ dans la mÊmoire d'une manière spÊcifique (la façon de compiler le noyau sera discutÊe plus loin dans ce chapitre).
* Le chargeur d'amorçage doit tenir dans le secteur d'amorçage (master boot record - MBR) d'un disque dur, dont la taille est de seulement 512 octets.
2-2-3. Le système d'exploitation▲
Le GRUB cède ensuite le contrôle au système d'exploitation en sautant à un nouvel emplacement mÊmoire. Avant ce saut mÊmoire, GRUB recherche un nombre magique pour s'assurer qu'il saute bien à un système d'exploitation et non à du code quelconque. Ce nombre magique fait partie de la spÊcification multiboot(19) à laquelle le GRUB se conforme. Dès que le GRUB a effectuÊ le saut, c'est le système d'exploitation qui a tout le contrôle de l'ordinateur.
2-3. Bonjour Cafebabe▲
Cette section dĂŠcrit comment mettre en Ĺuvre le plus petit OS qui puisse ĂŞtre utilisĂŠ avec GRUB. La seule chose que l'OS va faire est d'ĂŠcrire 0xCAFEBABE dans le registre eax (probablement, la plupart des gens n'appelleraient mĂŞme pas cela un système d'exploitation).
2-3-1. Compiler le système d'exploitation▲
Cette partie de l'OS doit être Êcrite en assembleur, car le C nÊcessite une pile qui n'est pas disponible (le chapitre Passage au C dÊcrit comment en crÊer une). Enregistrez le code suivant dans un fichier appelÊ loader.s :
global loader ; le symbole d'entrĂŠe pour ELF
NOMBRE_MAGIQUE equ 0x1BADB002 ; dĂŠfinit la constante nombre magique
DRAPEAUX equ 0x0 ; drapeaux multiboot
CHECKSUM equ -NOMBRE_MAGIQUE ; calcule la somme de contrĂ´le
; (nombre magique + somme de contrĂ´le + drapeaux doit ĂŞtre ĂŠgal Ă 0)
section .text: ; dĂŠbut de la section texte (code)
align 4 ; le code doit ĂŞtre alignĂŠ Ă 4 octets
dd NOMBRE_MAGIQUE ; ĂŠcrit le nombre magique en code machine,
dd DRAPEAUX ; les drapeaux,
dd CHECKSUM ; et la somme de contrĂ´le
loader: ; l'ĂŠtiquette du chargeur (dĂŠfinie comme point d'entrĂŠe dans le script de l'ĂŠditeur de liens)
mov eax, 0xCAFEBABE ; place le nombre 0xCAFEBABE dans le registre eax
.loop:
jmp .loop ; boucle infinieLa seule chose que cet OS va faire sera d'Êcrire le nombre très spÊcifique 0xCAFEBABE dans le registre eax. Il est très peu probable que le nombre 0xCAFEBABE s'y trouve dÊjà , si l'OS ne l'a pas Êcrit là .
Le fichier loader.s peut être compilÊ dans un fichier objet ELF de 32 bits avec la commande suivante :
nasm -f elf32 loader.s2-3-2. Ăditer les liens du noyau▲
Le code doit maintenant subir une ĂŠdition de liens afin de produire un fichier exĂŠcutable, ce qui nĂŠcessite une certaine rĂŠflexion supplĂŠmentaire par rapport Ă la liaison de la plupart des programmes. Nous voulons que le GRUB charge le noyau Ă une adresse mĂŠmoire supĂŠrieure ou ĂŠgale Ă 0x00100000 (1 mĂŠgaoctet [Mo]), parce que les adresses infĂŠrieures Ă 1 Mo sont utilisĂŠes par le GRUB lui-mĂŞme, par le BIOS et les E/S mappĂŠes en mĂŠmoire. Par consĂŠquent, le script suivant d'ĂŠdition de liens est nĂŠcessaire (il est ĂŠcrit pour GNU LD(20))Â :
ENTRY(loader) /* le nom de l'ĂŠtiquette du point d'entrĂŠe */
SECTIONS {
. = 0x00100000; /* le code doit ĂŞtre chargĂŠ Ă 1 Mo */
.text ALIGN (0x1000) : /* alignement Ă 4 ko */
{
*(.text) /* toutes les sections texte de tous les fichiers */
}
.rodata ALIGN (0x1000) : /* alignement Ă 4 ko */
{
*(.rodata*) /* toutes les sections de donnĂŠes en lecture seule, de tous les fichiers */
}
.data ALIGN (0x1000) : /* alignement Ă 4 ko */
{
*(.data) /* toutes les sections de donnĂŠes, de tous les fichiers */
}
.bss ALIGN (0x1000) : /* alignement Ă 4 ko */
{
*(COMMON) /* toutes les sections COMMON de tous les fichiers */
*(.bss) /* toutes les sections bss de tous les fichiers */
}
}Enregistrez le script d'Êdition de liens dans un fichier appelÊ link.ld. L'Êdition des liens de l'exÊcutable peut dÊsormais être exÊcutÊe avec la commande suivante :
ld -T link.ld -melf_i386 loader.o -o kernel.elfL'exĂŠcutable final s'appellera kernel.elf.
2-3-3. Obtenir GRUB▲
La version de GRUB que nous allons utiliser est GRUB Legacy, puisque l'image ISO de l'OS peut alors être gÊnÊrÊe sur les systèmes utilisant tant GRUB Legacy que GRUB 2. Plus prÊcisÊment, le chargeur d'amorçage stage2_eltorito de GRUB sera utilisÊ. Ce fichier peut être compilÊ à partir de GRUB 0.97 en tÊlÊchargeant les sources à l'adresse ftp://alpha.gnu.org/gnu/grub/grub-0.97.tar.gz. Cependant, le script configure ne fonctionne pas bien avec Ubuntu(21), alors le fichier binaire peut être tÊlÊchargÊ à partir de l'adresse http://littleosbook.github.com/files/stage2_eltorito. Copiez le fichier stage2_eltorito dans le dossier qui contient dÊjà les fichiers loader.s et link.ld.
2-3-4. CrĂŠer une image ISO▲
L'exĂŠcutable doit ĂŞtre placĂŠ sur un support qui peut ĂŞtre chargĂŠ par une machine virtuelle ou physique. Dans ce livre, nous allons utiliser comme support mĂŠdia les fichiers image ISO(22), mais on peut ĂŠgalement utiliser des images de type disquette, en fonction de ce que la machine virtuelle ou physique prend en charge.
Nous allons crÊer l'image ISO du noyau avec le programme genisoimage. Il faut d'abord crÊer un rÊpertoire contenant les fichiers qui seront sur l'image ISO. Les commandes suivantes crÊent le rÊpertoire et copient les fichiers à l'emplacement voulu :
mkdir -p iso/boot/grub # crĂŠe la structure du rĂŠpertoire
cp stage2_eltorito iso/boot/grub/ # copie le chargeur d'amorçage
cp kernel.elf iso/boot/ # copie le noyauUn fichier de configuration menu.lst pour GRUB doit être crÊÊ. Ce fichier indique à GRUB oÚ se trouve le noyau et configure quelques options :
default=0
timeout=0
title os
kernel /boot/kernel.elfPlacez le fichier menu.lst dans le rÊpertoire iso/boot/grub/. Le contenu du rÊpertoire iso devrait maintenant ressembler à ce qui suit :
iso
|-- boot
|-- grub
| |-- menu.lst
| |-- stage2_eltorito
|-- kernel.elfIl est alors possible de gÊnÊrer l'image ISO avec la commande suivante :
genisoimage -R \
-b boot/grub/stage2_eltorito \
-no-emul-boot \
-boot-load-size 4 \
-A os \
-input-charset utf8 \
-quiet \
-boot-info-table \
-o os.iso \
isoPour plus d'informations sur les options utilisĂŠes dans la commande, voir le manuel de genisoimage.
L'image ISO os.iso contient maintenant l'exÊcutable du noyau, le chargeur d'amorçage GRUB et le fichier de configuration.
2-3-5. ExĂŠcuter Bochs▲
Maintenant, nous pouvons exÊcuter l'OS dans l'Êmulateur Bochs en utilisant l'image ISO os.iso. Pour dÊmarrer, Bochs a besoin d'un fichier de configuration. Voici un exemple de fichier de configuration simple :
megs: 32
display_library: sdl
romimage: file=/usr/share/bochs/BIOS-bochs-latest
vgaromimage: file=/usr/share/bochs/VGABIOS-lgpl-latest
ata0-master: type=cdrom, path=os.iso, status=inserted
boot: cdrom
log: bochslog.txt
clock: sync=realtime, time0=local
cpu: count=1, ips=1000000Vous devrez peut-être modifier le chemin d'accès romimage et vgaromimage selon la façon dont vous avez installÊ Bochs. Vous trouverez plus d'informations sur le fichier de configuration de Bochs sur le site de Bochs(23).
Si vous avez enregistrÊ la configuration dans un fichier nommÊ bochsrc.txt, alors vous pouvez exÊcuter Bochs avec la commande suivante :
bochs -f bochsrc.txt -qL'option -f dit Ă Bochs d'utiliser le fichier de configuration donnĂŠ et -q lui dit d'ignorer le menu interactif de dĂŠmarrage. Vous devriez maintenant voir Bochs dĂŠmarrer et afficher une console avec quelques informations de GRUB.
Après avoir quittÊ Bochs, affichez le journal produit par celui-ci :
cat bochslog.txtVous devriez maintenant voir quelque part s'afficher le contenu des registres du processeur simulÊs par Bochs. Si vous trouvez dans la sortie RAX = 00000000CAFEBABE ou EAX = CAFEBABE (selon si vous utilisez Bochs avec ou sans le support pour 64 bits), alors votre système d'exploitation a dÊmarrÊ avec succès !
2-4. Lectures complĂŠmentaires▲
- Gustavo Duarte a ĂŠcrit un article approfondi sur ce qui se passe rĂŠellement quand un ordinateur x86 s'amorce, http://duartes.org/gustavo/blog/post/how-computers-boot-up
- Gustavo continue à dÊcrire ce que fait le noyau dans les stades très prÊcoces http://duartes.org/gustavo/blog/post/kernel-boot-process
- Le wiki de OSDev contient Êgalement un bel article sur l'amorçage d'un ordinateur x86 : http://wiki.osdev.org/Boot_Sequence
3. Passage au C▲
Ce chapitre va vous montrer comment utiliser le C comme langage de programmation pour le système d'exploitation à la place de l'assembleur. L'assembleur est très bon pour interagir avec le processeur et permet un contrôle maximum sur tous les aspects du code. Cependant, du moins pour les auteurs, le C est un langage beaucoup plus pratique à utiliser. Par consÊquent, nous aimerions utiliser le C autant que possible et utiliser l'assembleur uniquement là oÚ cela se justifie.
3-1. Configurer une pile▲
Une condition prĂŠalable pour l'utilisation du C est l'existence d'une pile, puisque tous les programmes non triviaux en C en utilisent une. La mise en place d'une pile n'est pas plus difficile que de faire pointer le registre esp vers la fin d'une zone de mĂŠmoire libre (rappelez-vous que sur l'architecture x86, la pile se dĂŠveloppe vers les adresses infĂŠrieures) qui est correctement alignĂŠe (l'alignement Ă 4 octets est recommandĂŠ d'un point de vue de la performance).
Nous pourrions faire pointer esp vers une zone alÊatoire dans la mÊmoire puisque, jusqu'à prÊsent, dans la mÊmoire ne se trouvent que GRUB, BIOS, le noyau du système d'exploitation et certaines E/S mappÊes en mÊmoire. Mais ce n'est pas une bonne idÊe, car nous ignorons la taille de la mÊmoire disponible, ou si la zone vers laquelle esp pointerait est utilisÊe par autre chose. Il vaut mieux rÊserver une partie de mÊmoire non initialisÊe dans la section bss du fichier ELF du noyau. Il est prÊfÊrable d'utiliser la section bss à la place de la section data, afin de rÊduire la taille de l'exÊcutable de l'OS. Puisqu'il comprend ELF, GRUB va allouer lors du chargement de l'OS tout espace mÊmoire rÊservÊ dans la section bss.
La pseudo-instruction resb(24) de NASM peut être utilisÊe pour dÊclarer des donnÊes non initialisÊes :
KERNEL_STACK_SIZE equ 4096 ; taille de la pile en octets
section .bss
align 4 ; alignement Ă 4 octets
kernel_stack: ; ĂŠtiquette pointant vers le dĂŠbut de la mĂŠmoire
resb KERNEL_STACK_SIZE ; rĂŠserve la pile pour le noyauIl n'y a pas lieu de se soucier de l'utilisation d'emplacements de mĂŠmoire non initialisĂŠs pour la pile, car il est impossible de lire un emplacement de la pile qui n'a pas ĂŠtĂŠ ĂŠcrit (Ă moins de bidouiller manuellement le pointeur de la pile). Un programme (correct) ne peut pas prĂŠlever un ĂŠlĂŠment de la pile sans l'y avoir prĂŠalablement mis. Par consĂŠquent, les emplacements de mĂŠmoire de la pile auront toujours ĂŠtĂŠ forcĂŠment ĂŠcrits avant d'ĂŞtre lus.
Le pointeur de la pile est alors configurÊ en faisant pointer esp vers la fin de la mÊmoire kernel_stack :
mov esp, kernel_stack + KERNEL_STACK_SIZE ; fait pointer esp vers le dĂŠbut de la
; pile (fin de la zone de mĂŠmoire)3-2. Appeler le code C Ă partir de l'assembleur▲
L'Êtape suivante est d'appeler une fonction C à partir du code en assembleur. Il existe de nombreuses conventions diffÊrentes pour faire cela(25). Ce livre utilise la convention d'appel cdecl, puisque c'est celle utilisÊe par GCC. La convention d'appel cdecl stipule que les arguments d'une fonction doivent être passÊs via la pile (sur x86). Les arguments de la fonction doivent être dÊposÊs sur la pile de droite à gauche, c'est-à -dire que l'on commence par l'argument le plus à droite. La valeur de retour de la fonction est placÊe dans le registre eax. Le code suivant montre un exemple :
/* La fonction C */
int somme_de_trois(int arg1, int arg2, int arg3)
{
return arg1 + arg2 + arg3;
}; Le code assembleur
external somme_de_trois ; la fonction somme_de_trois est dĂŠfinie ailleurs
push dword 3 ; arg3
push dword 2 ; arg2
push dword 1 ; arg1
call somme_de_trois ; appelle la fonction, le rĂŠsultat sera en eax3-2-1. Compacter les structures▲
Dans le reste de ce livre, vous rencontrerez souvent des  octets de configuration , qui sont des collections de bits dans un ordre très prÊcis. Ci-après, un exemple avec 32 bits :
Bit: | 31 24 | 23 8 | 7 0 |
Contenu: | index | adresse | config |Au lieu d'utiliser un entier non signÊ, unsigned int, pour le traitement de ces configurations, il est beaucoup plus facile d'utiliser les  structures compactÊes  :
struct exemple {
unsigned char config; /* bit 0 - 7 */
unsigned short adresse; /* bit 8 - 23 */
unsigned char index; /* bit 24 - 31 */
};Lors de l'utilisation de la struct de l'exemple prÊcÊdent, il n'y a aucune garantie que sa taille sera d'exactement 32 bits - le compilateur peut ajouter une marge de quelques bits entre les ÊlÊments pour diverses raisons, par exemple pour accÊlÊrer l'accès à l'ÊlÊment ou en raison des exigences fixÊes par le matÊriel et/ou le compilateur. Lorsque vous utilisez une struct pour reprÊsenter les octets de configuration, il est très important que le compilateur n'ajoute aucune marge, parce que la structure sera finalement traitÊe par le matÊriel comme un entier non signÊ sur 32 bits. L'attribut packed peut être utilisÊ pour forcer GCC à ne pas ajouter de marge :
struct exemple {
unsigned char config; /* bit 0 - 7 */
unsigned short adresse; /* bit 8 - 23 */
unsigned char index; /* bit 24 - 31 */
} __attribute__((packed));Notez que __attribute__((packed)) ne fait pas partie de la norme C, alors cela pourrait ne pas fonctionner avec tous les compilateurs C.
3-3. Compiler le code C▲
Lors de la compilation du code C pour le système d'exploitation, il faut utiliser un certain nombre d'options de compilation spÊcifiques de GCC, parce que le code C ne doit pas supposer la prÊsence d'une bibliothèque standard, puisqu'il n'y a aucune bibliothèque standard disponible pour notre OS. Pour plus d'informations sur ces options, voir le manuel de GCC.
Les options utilisÊes pour compiler le code C sont :
-m32 -nostdlib -nostdinc -fno-builtin -fno-stack-protector
-nostartfiles -nodefaultlibsComme toujours lors de l'Êcriture des programmes en C, nous recommandons d'activer tous les avertissements et de traiter les avertissements comme des erreurs :
-Wall -Wextra -WerrorMaintenant, vous pouvez crĂŠer dans un fichier appelĂŠ kmain.c une fonction kmain que vous appelez Ă partir de loader.s. Ă ce stade, kmain n'aura probablement besoin d'aucun argument (mais ce sera le cas dans les chapitres suivants).
3-4. Outils de compilation▲
C'est probablement aussi le bon moment pour mettre en place des outils de compilation pour faciliter la compilation et les tests d'exÊcution de l'OS. Nous vous recommandons d'utiliser make du GNU, mais beaucoup d'autres systèmes de compilation sont disponibles. Un simple Makefile pour l'OS pourrait ressembler à l'exemple suivant :
OBJECTS = loader.o kmain.o
CC = gcc
CFLAGS = -m32 -nostdlib -nostdinc -fno-builtin -fno-stack-protector \
-nostartfiles -nodefaultlibs -Wall -Wextra -Werror -c
LDFLAGS = -T link.ld -melf_i386
AS = nasm
ASFLAGS = -f elf
all: kernel.elf
kernel.elf: $(OBJECTS)
ld $(LDFLAGS) $(OBJECTS) -o kernel.elf
os.iso: kernel.elf
cp kernel.elf iso/boot/kernel.elf
genisoimage -R \
-b boot/grub/stage2_eltorito \
-no-emul-boot \
-boot-load-size 4 \
-A os \
-input-charset utf8 \
-quiet \
-boot-info-table \
-o os.iso \
iso
run: os.iso
bochs -f bochsrc.txt -q
%.o: %.c
$(CC) $(CFLAGS) $< -o $@
%.o: %.s
$(AS) $(ASFLAGS) $< -o $@
clean:
rm -rf *.o kernel.elf os.isoLe contenu de votre rÊpertoire de travail devrait ressembler à ce qui suit :
.
|-- bochsrc.txt
|-- iso
| |-- boot
| |-- grub
| |-- menu.lst
| |-- stage2_eltorito
|-- kmain.c
|-- loader.s
|-- MakefileVous devriez maintenant être en mesure de dÊmarrer le système d'exploitation par une simple commande make run, qui va compiler le noyau et le dÊmarrer dans Bochs (comme dÊfini dans le Makefile ci-dessus).
3-5. Lecture complĂŠmentaire▲
Le livre Le langage C, Deuxième Êdition (Dunod), de Brian Kernighan et Dennis Ritchie est idÊal pour apprendre tous les aspects du C.
4. Les sorties▲
Ce chapitre prÊsente la façon d'afficher du texte sur la console et d'Êcriture des donnÊes sur le port sÊrie. En outre, nous allons crÊer notre premier pilote ou driver, c'est-à -dire programme qui agit comme une couche intermÊdiaire entre le noyau et le matÊriel, en fournissant un niveau d'abstraction supÊrieur à la communication directe avec le matÊriel. La première partie de ce chapitre traite de la crÊation d'un pilote pour le tampon de trame ou framebuffer(26), afin d'être en mesure d'afficher du texte sur la console. La seconde partie montre comment crÊer un pilote pour le port sÊrie. Bochs peut stocker la sortie du port sÊrie dans un fichier, crÊant de fait un mÊcanisme de journalisation pour le système d'exploitation.
4-1. Interagir avec le matĂŠriel▲
Il y a gÊnÊralement deux façons diffÊrentes d'interagir avec le matÊriel, les E/S mappÊes en mÊmoire et les ports d'E/S.
Si le matĂŠriel utilise les E/S mappĂŠes en mĂŠmoire, alors vous pouvez ĂŠcrire Ă une adresse mĂŠmoire spĂŠcifique et le matĂŠriel sera mis Ă jour avec les nouvelles donnĂŠes. Un exemple est reprĂŠsentĂŠ par le tampon de trame, qui sera dĂŠcrit plus en dĂŠtail plus tard. Par exemple, si vous ĂŠcrivez la valeur 0x410F Ă l'adresse 0x000B8000, vous verrez la lettre A en blanc sur un fond noir (voir la section sur le tampon de trameLe tampon de trame pour plus de dĂŠtails).
Si le matÊriel utilise des ports E/S, alors les instructions assembleur out et in doivent être utilisÊes pour communiquer avec le matÊriel. L'instruction out prend deux paramètres : l'adresse du port d'E/S et les donnÊes à envoyer. L'instruction in prend un seul paramètre, l'adresse du port d'E/S, et retourne les donnÊes à partir du matÊriel. On peut penser aux ports d'E/S comme communiquant avec le matÊriel de la même manière que vous communiquez avec un serveur en utilisant les sockets. Le curseur (le rectangle clignotant) du tampon de trame est un exemple du matÊriel sur un PC contrôlÊ via les ports d'E/S.
4-2. Le tampon de trame▲
Le tampon de trame est un dispositif matĂŠriel qui est capable d'afficher Ă l'ĂŠcran le contenu de la mĂŠmoire tampon. Il dispose de 80 colonnes et 25 lignes, et les indices des lignes et des colonnes commencent Ă 0 (les lignes sont donc numĂŠrotĂŠes de 0 Ă 24).
4-2-1. Ăcrire du texte▲
L'Êcriture d'un texte à la console via le tampon de trame est faite avec des E/S mappÊes en mÊmoire. L'adresse de dÊpart des E/S mappÊes en mÊmoire pour le tampon de trame est 0x000B8000(27). La mÊmoire est divisÊe en cellules de 16 bits, oÚ les 16 bits dÊterminent à la fois le caractère, la couleur d'avant-plan et la couleur d'arrière-plan. Les huit bits les plus ÊlevÊs reprÊsentent la valeur ASCII(28) du caractère, les bits de 7 à 4, l'arrière-plan et les bits de 3 à 0, le premier plan, comme on peut le voir ci-dessous :
Bit : | 15 14 13 12 11 10 9 8 | 7 6 5 4 | 3 2 1 0 |
Contenu : | ASCII |Av.-plan | Ar.-plan|Les couleurs disponibles sont reprises dans le tableau suivant :
|
Couleur |
Valeur |
Couleur |
Valeur |
Couleur |
Valeur |
Couleur |
Valeur |
|---|---|---|---|---|---|---|---|
|
Noir |
0 |
Rouge |
4 |
Gris foncĂŠ |
8 |
Rouge clair |
12 |
|
Bleu |
1 |
Magenta |
5 |
Bleu clair |
9 |
Magenta clair |
13 |
|
Vert |
2 |
Brun |
6 |
Vert clair |
10 |
Brun clair |
14 |
|
Cyan |
3 |
Gris clair |
7 |
Cyan clair |
11 |
Blanc |
15 |
La première cellule correspond à la ligne zÊro, colonne zÊro sur la console. En utilisant une table ASCII, on peut voir que le caractère A correspond à la valeur 65 ou 0x41. Par consÊquent, pour Êcrire le caractère A avec un avant-plan vert (2) et le fond gris foncÊ (8) à l'endroit (0,0), l'instruction de code assembleur suivante est utilisÊe :
mov [0x000B8000], 0x4128La deuxième cellule correspond alors à la ligne zÊro, colonne 1, et son adresse est donc :
0x000B8000 + 16 = 0x000B8010L'Êcriture au tampon de trame peut Êgalement être faite en C, en traitant l'adresse 0x000B8000 comme un pointeur de char, char *tt = (char *) 0x000B8000. Donc, l'Êcriture du caractère A à l'endroit (0,0) avec l'avant-plan vert et sur fond gris foncÊ devient :
tt[0] = 'A';
tt[1] = 0x28;Le code suivant montre comment incorporer cela dans une fonction :
/** tt_ecrire_cellule :
* Ăcrit un caractère avec l'avant-plan et l'arrière-plan donnĂŠs Ă la position i
* dans le tampon de trame.
*
* @param i L'emplacement dans le tampon de trame
* @param c Le caractère
* @param fg La couleur de l'avant-plan
* @param bg La couleur de l'arrière-plan
*/
void tt_ecrire_cellule(unsigned int i, char c, unsigned char fg, unsigned char bg)
{
tt[i] = c;
tt[i + 1] = ((fg & 0x0F) << 4) | (bg & 0x0F)
}La fonction peut être utilisÊe comme ceci :
#define TT_VERT 2
#define TT_GRIS_FONCE 8
tt_ecrire_cellule(0, 'A', TT_VERT, TT_GRIS_FONCE);4-2-2. DĂŠplacer le curseur▲
Le dÊplacement du curseur du tampon de trame se fait via deux ports diffÊrents d'E/S. La position du curseur est dÊterminÊe par un entier sur 16 bits : 0 signifie ligne zÊro, colonne zÊro ; 1 signifie ligne zÊro, colonne 1 ; 80 signifie ligne 1, colonne zÊro et ainsi de suite. Comme la position prend 16 bits alors que l'argument de l'instruction assembleur out a une taille de 8 bits, la position doit être envoyÊe en deux fois, d'abord les 8 premiers bits puis les 8 bits suivants. Le tampon de trame possède deux ports d'E/S, un pour accepter les donnÊes et un pour dÊcrire les donnÊes reçues. Le port 0x3D4(29) est celui qui dÊcrit les donnÊes et le port 0x3D5 est pour les donnÊes mêmes.
Pour rÊgler le curseur sur la ligne 1, colonne zÊro (la position 80 = 0x0050), on pourrait utiliser les instructions suivantes en assembleur :
out 0x3D4, 14 ; 14 dit au tampon de trame d'attendre les 8 bits supĂŠrieurs de la position
out 0x3D5, 0x00 ; envoyer les 8 bits supĂŠrieurs de 0x0050
out 0x3D4, 15 ; 15 dit au tampon de trame d'attendre les 8 bits infĂŠrieurs de la position
out 0x3D5, 0x50 ; envoyer les 8 bits infÊrieurs de 0x0050L'instruction en assembleur out ne peut pas être exÊcutÊe directement en C. Par consÊquent, c'est une bonne idÊe de l'englober dans une fonction Êcrite en assembleur qui peut être accÊdÊe par le code C via la norme de l'appel cdecl :
global outb ; rend l'ĂŠtiquette outb visible en dehors de ce fichier
; outb - envoie un octet vers un port E/S
; pile : [esp + 8] l'octet de donnĂŠes
; [esp + 4] le port E/S
; [esp ] l'adresse de retour
outb:
mov al, [esp + 8] ; dĂŠplace les donnĂŠes Ă envoyer dans le registre al
mov dx, [esp + 4] ; dĂŠplace l'adresse du port E/S dans le registre dx
out dx, al ; envoie les donnĂŠes vers le port E/S
ret ; retour vers la fonction appelanteEn stockant cette fonction dans un fichier nommĂŠ io.s et en crĂŠant aussi un fichier en-tĂŞte io.h, l'instruction assembleur out peut ĂŞtre accĂŠdĂŠe convenablement Ă partir du code CÂ :
#ifndef INCLUDE_IO_H
#define INCLUDE_IO_H
/** outb:
* Envoie les donnĂŠes vers le port E/S donnĂŠ. DĂŠfini en io.s
*
* @param port Le port E/S vers lequel envoyer les donnĂŠes
* @param data Les donnĂŠes Ă envoyer vers le port E/S
*/
void outb(unsigned short port, unsigned char data);
#endif /* INCLUDE_IO_H */Le dĂŠplacement du curseur peut maintenant ĂŞtre englobĂŠ dans une fonction en CÂ :
#include "io.h"
/* Les ports d'E/S */
#define TT_PORT_COMMANDE 0x3D4
#define TT_PORT_DATA 0x3D5
/* Les commandes du port d'E/S */
#define TT_COMMANDE_OCTET_SUP 14
#define TT_COMMANDE_OCTET_INF 15
/** tt_deplace_curseur:
* DĂŠplace le curseur du tampon de trame Ă la position donnĂŠe
*
* @param pos La nouvelle position du curseur
*/
void tt_deplace_curseur(unsigned short pos)
{
outb(TT_PORT_COMMANDE, TT_COMMANDE_OCTET_SUP);
outb(TT_PORT_DATA, ((pos >> 8) & 0x00FF));
outb(TT_PORT_COMMANDE, TT_COMMANDE_OCTET_INF);
outb(TT_PORT_DATA, pos & 0x00FF);
}4-2-3. Le pilote▲
Le pilote doit fournir une interface utilisÊe par le reste du code de l'OS pour interagir avec le tampon de trame. Il n'y a pas de bon ou de mauvais choix en ce que la fonctionnalitÊ de l'interface doit fournir, mais une suggestion est d'avoir une fonction write, avec la dÊclaration suivante :
int write(char *buf, unsigned int len);La fonction write Êcrit à l'Êcran le contenu de longueur len du tampon buf. Elle doit faire avancer automatiquement le curseur après l'Êcriture d'un caractère et faire dÊfiler l'Êcran si nÊcessaire.
4-3. Les ports sĂŠrie▲
Le port sÊrie (30) est une interface pour la communication entre dispositifs matÊriels. Même s'il est disponible sur la quasi-totalitÊ des cartes mères, il est de nos jours moins souvent disponible à l'utilisateur sous la forme d'un connecteur DE-9 (à 9 broches). Le port sÊrie est facile à utiliser et, surtout, peut être utilisÊ comme un outil de journalisation dans Bochs. Si un ordinateur a un support pour un port sÊrie, alors il a gÊnÊralement le support pour plusieurs ports sÊrie ; mais nous en utiliserons un seul, car nous allons utiliser les ports sÊrie uniquement pour la journalisation. En outre, nous allons utiliser les ports sÊrie uniquement pour la sortie, pas pour l'entrÊe. Les ports sÊrie sont complètement contrôlÊs via les ports E/S.
4-3-1. Configurer le port sĂŠrie▲
Les premières donnÊes qui doivent être envoyÊes au port sÊrie sont des donnÊes de configuration. Pour que deux pÊriphÊriques matÊriels soient en mesure de communiquer entre eux, ils doivent se mettre d'accord sur un certain nombre de choses. Ces choses incluent :
- la vitesse utilisĂŠe pour envoyer des donnĂŠes (dĂŠbit en bits par seconde ou bauds)Â ;
- si une vĂŠrification d'erreur doit ĂŞtre utilisĂŠe pour les donnĂŠes (bit de paritĂŠ, bits d'arrĂŞt)Â ;
- le nombre de bits qui reprĂŠsentent une unitĂŠ de donnĂŠes (bits de donnĂŠes).
4-3-2. Configurer la ligne▲
Configurer la ligne signifie configurer la façon dont les donnÊes sont envoyÊes sur la ligne. Le port sÊrie dispose d'un port E/S, le port de commande de ligne, qui est utilisÊ pour la configuration.
La vitesse d'envoi de donnÊes sera dÊfinie en premier. Le port sÊrie possède une horloge interne qui fonctionne à 115 200 Hz. DÊfinir la vitesse signifie envoyer un diviseur vers le port sÊrie, par exemple l'envoi de 2 rÊsultats à une vitesse de 115 200/2 = 57 600 Hz.
Le diviseur est un nombre sur 16 bits, mais nous pouvons envoyer seulement 8 bits à la fois. Nous devons donc envoyer une instruction disant au port sÊrie d'attendre d'abord les 8 bits les plus ÊlevÊs, puis les 8 bits infÊrieurs. Cela se fait par l'envoi de 0x80 au port de commande de ligne. Un exemple est prÊsentÊ ci-dessous :
#include "io.h" /* io.h est implÊmentÊ dans la section  DÊplacer le curseur  */
/* Les ports E/S */
/* Tous les ports E/S sont calculĂŠs par rapport au port de donnĂŠes. Cela, parce que
* tous les ports sĂŠrie (COM1, COM2, COM3, COM4) ont leurs ports dans le mĂŞme
* ordre, mais ils commencent Ă des valeurs diffĂŠrentes.
*/
#define SERIE_COM1_BASE 0x3F8 /* le port COM1 base */
#define SERIE_DATA_PORT(base) (base)
#define SERIE_FIFO_COMMAND_PORT(base) (base + 2)
#define SERIE_LIGNE_COMMAND_PORT(base) (base + 3)
#define SERIE_MODEM_COMMAND_PORT(base) (base + 4)
#define SERIE_LIGNE_STATUS_PORT(base) (base + 5)
/* Les commandes de port E/S */
/* SERIE_LIGNE_ACTIVER_DLAB:
* Dit au port sĂŠrie d'attendre en premier les 8 bits les plus ĂŠlevĂŠs sur le port de donnĂŠes,
* puis les 8 bits infĂŠrieurs suivront
*/
#define SERIE_LIGNE_ACTIVER_DLAB 0x80
/** serie_configurer_baud_rate:
* DĂŠfinit la vitesse d'envoi des donnĂŠes. La vitesse par dĂŠfaut d'un port sĂŠrie
* est de 115200 bits/s. L'argument est un diviseur de ce nombre, alors la vitesse
* rĂŠsultante devient (115200 / diviseur) bits/s.
*
* @param com Le port COM Ă configurer
* @param diviseur Le diviseur
*/
void serie_configurer_baud_rate(unsigned short com, unsigned short diviseur)
{
outb(SERIE_LIGNE_COMMAND_PORT(com),
SERIE_LIGNE_ACTIVER_DLAB);
outb(SERIE_DATA_PORT(com),
(divisor >> 8) & 0x00FF);
outb(SERIE_DATA_PORT(com),
divisor & 0x00FF);
}Il faut configurer la façon dont les donnÊes doivent être envoyÊes. Cela aussi se fait via le port de commande de la ligne, en envoyant un octet. La disposition des 8 bits se prÊsente comme suit :
Bit : | 7 | 6 | 5 4 3 | 2 | 1 0 |
Contenu : | d | b | prty | s | dl |Une description de chaque nom se trouve dans le tableau ci-dessous :
|
Nom |
Description |
|---|---|
|
d |
Active (d = 1) ou dĂŠsactive (d = 0) DLAB |
|
b |
Si le contrĂ´le de l'interruption est activĂŠ (b = 1) ou dĂŠsactivĂŠ (b = 0) |
|
prty |
Le nombre de bits de paritĂŠ Ă utiliser |
|
s |
Le nombre de bits d'arrĂŞt Ă utiliser (s = 0 correspond Ă 1, s = 1 correspond Ă 1,5 ou 2 |
|
dl |
DĂŠcrit la longueur des donnĂŠes |
Nous allons utiliser principalement la valeur 0x03 de la norme(30), qui signifie une longueur de 8 bits, sans bit de paritÊ, un bit d'arrêt et contrôle de l'interruption Break dÊsactivÊ. Cette valeur est envoyÊe au port de commande de ligne, comme on le voit dans l'exemple suivant :
/** configurer_ligne_serie :
* Configure la ligne du port sĂŠrie donnĂŠ. Le port est configurĂŠ pour avoir une
* longueur des donnĂŠes de 8 bits, aucun bit de paritĂŠ, un bit d'arrĂŞt et le
* contrĂ´le d'interruption dĂŠsactivĂŠ.
*
* @param com Le port sĂŠrie Ă configurer
*/
void configurer_ligne_serie(unsigned short com)
{
/* Bit : | 7 | 6 | 5 4 3 | 2 | 1 0 |
* Contenu : | d | b | prty | s | dl |
* Valeur : | 0 | 0 | 0 0 0 | 0 | 1 1 | = 0x03
*/
outb(SERIE_LIGNE_COMMAND_PORT(com), 0x03);
}L'article (31) sur OSDev offre une explication plus approfondie des valeurs.
4-3-3. Configurer les tampons▲
Lorsque les donnÊes sont transmises via le port sÊrie, elles sont placÊes dans des tampons, aussi bien lors de la rÊception et lors de l'envoi des donnÊes. De cette façon, si vous envoyez au port sÊrie des donnÊes plus vite qu'il ne peut les envoyer sur la ligne, elles seront mises en tampon. Cependant, si vous envoyez trop de donnÊes trop vite, la mÊmoire tampon sera pleine et les donnÊes seront perdues. Autrement dit, les tampons sont des files d'attente FIFO (premier entrÊ, premier sorti). L'octet de configuration de file d'attente FIFO ressemble à ce qui suit :
Bit : | 7 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Contenu : | lvl | bs | r | dma | clt | clr | e |Une description de chaque nom se trouve dans le tableau ci-dessous :
|
Nom |
Description |
|---|---|
|
lvl |
Le nombre de bits qui doivent ĂŞtre stockĂŠs dans les tampons FIFO |
|
bs |
Indique si les tampons doivent avoir une taille de 16 ou de 64 octets |
|
r |
RĂŠservĂŠ pour usage dans le futur |
|
dma |
Indique comment il faut accĂŠder au port sĂŠrie de donnĂŠes |
|
clt |
Vide le tampon FIFO de transmission |
|
clr |
Vide le tampon FIFO du rĂŠcepteur |
|
e |
Indique si le tampon FIFO doit ĂŞtre activĂŠ ou pas |
Nous utilisons la valeur 0xC7, qui :
- active FIFOÂ ;
- vide les deux files FIFO, tant celle de transmission que celle du rÊcepteur ;
- utilise une taille de file de 14 octets.
Le WikiBook sur la programmation sĂŠrie(31) explique les valeurs plus en dĂŠtail.
4-3-4. Configurer le modem▲
Le registre de contrôle du modem est utilisÊ pour un contrôle matÊriel très simple du flux via les connecteurs Ready To Transmit - RTS ( prêt à transmettre ) et Data Terminal Ready - DTR ( terminal de donnÊes prêt ). Lors de la configuration du port sÊrie, nous voulons mettre RTS et DTR à 1, ce qui signifie que nous sommes prêts à envoyer des donnÊes.
L'octet de configuration du modem est indiquÊ ci-dessous :
Bit : | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Contenu : | r | r | af | lb | ao2 | ao1 | rts | dtr |Une description de chaque nom se trouve dans le tableau ci-dessous :
|
Nom |
Description |
|---|---|
|
r |
RĂŠservĂŠ |
|
af |
ContrĂ´le du flux automatique activĂŠ |
|
lb |
Mode loopback ou  diagnostic  (utilisÊ pour dÊboguer les ports sÊrie) |
|
ao2 |
Sortie auxiliaire 2, utilisĂŠe pour recevoir des interruptions |
|
ao1 |
Sortie auxiliaire 1 |
|
rts |
Ready To Transmit |
|
dtr |
Data Terminal Ready |
Nous n'avons pas besoin d'activer les interruptions, parce que nous ne gÊrerons aucune donnÊe reçue. Par consÊquent, nous utilisons la valeur de configuration 0x03 = 00000011 (RTS = 1 et DTR = 1).
4-3-5. Ăcrire des donnĂŠes sur le port sĂŠrie▲
L'ĂŠcriture de donnĂŠes sur le port sĂŠrie se fait via le port d'E/S de donnĂŠes. Cependant, avant l'ĂŠcriture, la file FIFO de transmission doit ĂŞtre vide (toutes les ĂŠcritures prĂŠcĂŠdentes doivent ĂŞtre finies). La file FIFO de transmission est vide si le bit 5 de l'ĂŠtat de la ligne du port E/S est ĂŠgal Ă un.
La lecture du contenu d'un port E/S se fait grâce à l'instruction in en assembleur. Il n'est pas possible d'utiliser cette instruction assembleur à partir du code C, par consÊquent, elle doit être enveloppÊe (de la même manière que l'instruction en assembleur out) :
global inb
; inb - retourne un octet reçu du port E/S donnÊ
; pile : [esp + 4] L'adresse du port E/S donnĂŠ
; [esp ] L'adresse de retour
inb:
mov dx, [esp + 4] ; dĂŠplace l'adresse du port E/S donnĂŠ dans le registre dx
in al, dx ; lit un octet reçu du port E/S et le stocke dans le registre al
ret ; retourne l'octet lu/* dans le fichier io.h */
/** inb:
* Lit un octet reçu d'un port E/S.
*
* @param port L'adresse du port E/S
* @return L'octet lu
*/
unsigned char inb(unsigned short port);Ensuite, la vĂŠrification si la file FIFO de transmission est vide peut ĂŞtre faite par le code CÂ :
#include "io.h"
/** serie_est_transmiss_fifo_vide :
* VĂŠrifie si la file FIFO de transmission est vide ou pas pour le port COM donnĂŠ.
*
* @param com Le port COM
* @return 0 si la file FIFO n'est pas vide
* 1 si la file FIFO de transmission est vide
*/
int serie_is_transmiss_fifo_vide(unsigned int com)
{
/* 0x20 = 0010 0000 */
return inb(SERIE_LIGNE_STATUS_PORT(com)) & 0x20;
}L'ĂŠcriture sur un port sĂŠrie signifie tourner tant que la file de transmission FIFO n'est pas vide, puis ĂŠcrire les donnĂŠes sur le port E/S de donnĂŠes.
4-3-6. Configurer Bochs▲
Pour enregistrer la sortie du premier port sÊrie, le fichier de configuration de Bochs, bochsrc.txt, doit être mis à jour. La configuration com1 instruit Bochs afin de gÊrer le premier port sÊrie :
com1: enabled=1, mode=file, dev=com1.outLa sortie du premier port sĂŠrie sera maintenant stockĂŠe dans le fichier com1.out.
4-3-7. Le pilote▲
Nous vous recommandons d'implĂŠmenter pour le port sĂŠrie une fonction write similaire Ă la fonction du mĂŞme nom du pilote pour le tampon de trame. Pour ĂŠviter les conflits de noms, il est judicieux de nommer les fonctions tt_write et serie_write pour les distinguer.
Nous recommandons ĂŠgalement que vous essayiez d'ĂŠcrire une fonction similaire Ă printf, voir la section 7.3 dans (8). Cette fonction printf pourrait prendre un argument supplĂŠmentaire pour dĂŠcider sur quel pĂŠriphĂŠrique ĂŠcrire la sortie (tampon de trame ou port sĂŠrie).
Une dernière recommandation est de crÊer un moyen de distinguer le degrÊ de sÊvÊritÊ des messages du journal, par exemple en faisant prÊcÊder les messages par DEBUG, INFO ou ERROR.
4-4. Lectures complĂŠmentaires▲
- Le livre  Serial programming  (disponible sur WikiBooks) a une section excellente au sujet de la programmation du port sÊrie, http://en.wikibooks.org/wiki/Serial_Programming/8250_UART_Programming#UART_Registers;
- Le wiki OSDev a une page contenant beaucoup d'informations au sujet des ports sĂŠrie, http://wiki.osdev.org/Serial_ports.
5. Segmentation▲
La segmentation en x86 signifie l'accès à la mÊmoire par segments. Les segments sont des zones de l'espace d'adressage, qui peuvent Êventuellement se chevaucher, spÊcifiÊes par une adresse de base et une limite. Pour accÊder à un octet en mÊmoire segmentÊe, vous utilisez une adresse logique de 48 bits : 16 bits qui spÊcifient le segment et 32 bits qui spÊcifient le dÊcalage souhaitÊ dans ce segment. Le dÊcalage (offset) est ajoutÊ à l'adresse de base du segment, et l'adresse linÊaire rÊsultante est vÊrifiÊe par rapport à la limite du segment - voir la figure ci-dessous. Si tout se passe bien (y compris les contrôles de droits d'accès, ignorÊs pour l'instant) le rÊsultat est une adresse linÊaire. Lorsque la pagination est dÊsactivÊe, l'espace d'adressage linÊaire est mappÊ 1:1 à l'espace d'adressage physique, et l'accès à la mÊmoire physique peut avoir lieu. (Voir le chapitre PaginationPagination pour savoir comment activer la pagination.)
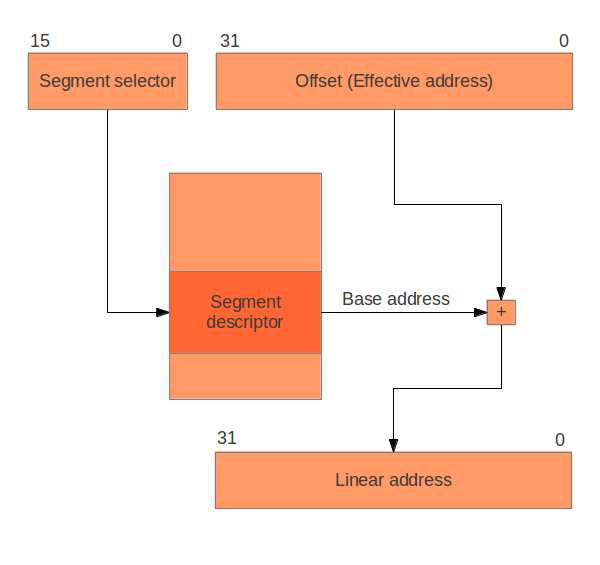
Pour activer la segmentation, vous devez mettre en place une table qui dÊcrit chaque segment - une table de descripteurs de segment. Dans x86, il existe deux types de tables de descripteurs : la table de descripteurs globaux (Global Descriptor Table - GDT) et les tables de descripteurs locaux (Local Descriptor Table - LDT). Une LDT est mise en place et gÊrÊe par des processus de l'espace utilisateur, et tous les processus ont leur propre LDT. Les LDT peuvent être utilisÊes si vous dÊsirez un modèle de segmentation plus complexe, nous ne l'utiliserons pas. La GDT est partagÊe par tout le monde - elle est globale.
Comme nous le verrons dans les sections sur la mĂŠmoire virtuelle et la pagination, la segmentation est rarement utilisĂŠe en dehors d'une configuration minimale, semblable Ă ce que nous mettons en place ci-dessous.
5-1. AccĂŠder Ă la mĂŠmoire▲
La plupart du temps, lors de l'accès en mÊmoire, il n'est pas besoin de spÊcifier explicitement le segment à utiliser. Le processeur dispose de six registres de segment de 16 bits : cs, ss, ds, es, gs et fs. Le registre cs (code segment) est le registre de segment du code et spÊcifie le segment à utiliser lorsqu'on rÊcupère des instructions. Le registre ss (stack segment) est utilisÊ chaque fois que l'on accède à la pile (à travers le pointeur de pile esp), et ds (data segment) est utilisÊ pour d'autres accès aux donnÊes. L'OS est libre d'utiliser les registres es, gs et fs comme il veut.
Voici un exemple montrant l'utilisation implicite des registres de segment :
func:
mov eax, [esp+4]
mov ebx, [eax]
add ebx, 8
mov [eax], ebx
retL'exemple ci-dessus peut être comparÊ à l'exemple suivant, qui montre une utilisation explicite des registres de segments :
func:
mov eax, [ss:esp+4]
mov ebx, [ds:eax]
add ebx, 8
mov [ds:eax], ebx
retVous n'avez pas besoin d'utiliser ss pour stocker le sĂŠlecteur de segment de la pile, ou ds pour le sĂŠlecteur de segment de donnĂŠes. Vous pourriez stocker le sĂŠlecteur de segment de la pile dans ds et vice versa. Toutefois, pour pouvoir utiliser le style implicite indiquĂŠ ci-dessus, vous devez stocker les sĂŠlecteurs de segments dans leurs registres prĂŠvus Ă cette fin.
Les descripteurs de segments et leurs champs sont dĂŠcrits dans la figure 3-8 dans le manuel Intel(32).
5-2. La table de descripteurs globaux (GDT)▲
Une GDT/LDT est un  tableau  de descripteurs de segment de 8 octets. Le premier descripteur dans le GDT est toujours un descripteur null et ne peut jamais être utilisÊ pour accÊder à la mÊmoire. Au moins deux descripteurs de segment (plus le descripteur null) sont nÊcessaires pour la GDT, parce que le descripteur contient plus d'informations que seulement les champs base et limite. Les plus importants pour nous sont le champ Type et le champ Descripteur de niveau de privilège (Descriptor Privilege Level - DPL).
Le Tableau 3-1 dans le chapitre 3 du manuel Intel (33) spÊcifie les valeurs pour le champ Type. Il montre que le champ Type ne peut pas être en même temps accessible en Êcriture et exÊcutable. Par consÊquent, deux segments sont nÊcessaires : un segment pour l'exÊcution du code à mettre en cs (Type est en exÊcution seule ou en exÊcution et lecture) et un segment pour les donnÊes de lecture et d'Êcriture (Type est en lecture/Êcriture) à mettre dans les autres registres de segment.
Le DPL prÊcise les niveaux de privilèges nÊcessaires pour utiliser le segment. Le processeur x86 autorise quatre niveaux de privilèges (PL), de 0 à 3, oÚ PL0 est le plus privilÊgiÊ. Dans la plupart des systèmes d'exploitation (par ex. Linux et Windows), seulement PL0 et PL3 sont utilisÊs. Cependant, certains systèmes d'exploitation, tels que MINIX, font usage de tous les niveaux. Le noyau devrait être en mesure de tout faire, donc il utilise des segments avec DPL dÊfini à 0 (Êgalement appelÊ  mode du noyau ). Le niveau de privilège courant (CPL) est dÊterminÊ par le sÊlecteur de segment dans le registre cs.
Les descripteurs de segments nĂŠcessaires sont repris ci-dessous.
|
Index |
Offset |
Nom |
Plage d'adressage |
Type |
DPL |
|---|---|---|---|---|---|
|
0 |
0x00 |
descripteur null |
|||
|
1 |
0x08 |
segment de code du noyau |
0x00000000 - 0xFFFFFFFF |
RX |
PL0 |
|
2 |
0x10 |
segment de donnĂŠes du noyau |
0x00000000 - 0xFFFFFFFF |
RW |
PL0 |
Notez que les segments se chevauchent - ils englobent tous deux la totalitÊ de l'espace d'adressage linÊaire. Dans notre configuration minimale, nous utiliserons uniquement la segmentation pour obtenir des niveaux de privilèges. Voir le manuel Intel (33), chapitre 3, pour plus de dÊtails sur les autres champs de descripteur.
5-3. Charger la GDT▲
Le chargement de la GDT dans le processeur se fait avec l'instruction en assembleur lgdt, qui a besoin de l'adresse d'une structure spÊcifiant le dÊbut et la taille de la GDT. Il est plus facile à coder ces informations en utilisant une  structure compactÊeCompacter les structures , comme dans l'exemple suivant :
struct gdt {
unsigned int address;
unsigned short size;
} __attribute__((packed));Si le registre eax contient l'adresse d'une telle structure, la GDT peut être chargÊe avec le code assembleur ci-dessous :
lgdt [eax]Rendre cette instruction disponible à partir de C pourrait faciliter les choses, de la même manière qu'avec les instructions assembleur in et out.
Après le chargement de la GDT, les registres de segment doivent être chargÊs avec leurs sÊlecteurs de segment correspondants. Le contenu d'un sÊlecteur de segment est dÊcrit dans la figure et le tableau ci-dessous :
Bit : | 15 3 | 2 | 1 0 |
Contenu : | offset (index) | ti | rpl ||
Nom |
Description |
|---|---|
|
rpl |
Niveau de privilège demandÊ - pour le moment, nous voulons exÊcuter en PL0. |
|
ti |
Indicateur de table. 0 signifie qu'il s'agit d'un segment de GDT, 1 reprĂŠsente un segment de LTD. |
|
offset (index) |
DĂŠcalage dans la table des descripteurs. |
Le dÊcalage du sÊlecteur de segment est ajoutÊ au dÊbut de la GDT pour obtenir l'adresse du descripteur de segment : 0x08 pour le premier descripteur et 0x10 pour la deuxième, puisque chaque descripteur est de 8 octets. Le niveau de privilège requis (Requested Privilege Level - RPL) doit être 0 puisque le noyau de l'OS doit s'exÊcuter dans le niveau de privilège 0.
Le chargement des registres de sÊlecteur de segment est facile pour les registres de donnÊes - il suffit de copier les dÊcalages corrects dans les registres :
mov ds, 0x10
mov ss, 0x10
mov es, 0x10
.
.
.Pour charger cs, nous devons faire un  saut à distance  :
; ce code utilise le cs prĂŠcĂŠdent
jmp 0x08:flush_cs ; spĂŠcifiez le cs lors du saut Ă flush_cs
flush_cs:
; maintenant, nous avons modifiÊ cs à 0x08Un saut à distance est un saut oÚ nous spÊcifions explicitement l'adresse logique complète de 48 bits : le sÊlecteur de segment à utiliser et l'adresse absolue oÚ sauter. Cela dÊfinira d'abord cs à 0x08, puis sautera à flush_cs en utilisant son adresse absolue.
5-4. Lectures complĂŠmentaires▲
- Le chapitre 3 du manuel Intel (33) est rempli de dĂŠtails de bas niveau et techniques sur la segmentation.
- Le wiki de OSDev a une page sur la segmentation : http://wiki.osdev.org/Segmentation
- La page Wikipedia sur la segmentation sous x86 pourrait être utile dans la recherche : http://en.wikipedia.org/wiki/X86_memory_segmentation, https://fr.wikipedia.org/wiki/Segmentation_(informatique)
6. Interruptions et saisie▲
Maintenant que l'OS peut produire des sorties, ce serait bien si l'on pouvait Êgalement obtenir quelques entrÊes. Le système d'exploitation doit être capable de gÊrer les interruptions pour lire des informations à partir du clavier. Une interruption se produit lorsqu'un dispositif matÊriel, tel que le clavier, le port sÊrie ou l'horloge signale au processeur que l'Êtat du dispositif a changÊ. Le processeur lui-même peut Êgalement envoyer des interruptions dues à des erreurs de programme, par exemple lorsqu'un programme rÊfÊrence de la mÊmoire à laquelle il n'a pas accès, ou quand un programme divise un nombre par zÊro. Enfin, il y a aussi les interruptions logicielles, qui sont les interruptions causÊes par l'instruction assembleur int ; elles sont souvent utilisÊes pour les appels système.
6-1. Les gestionnaires d'interruptions▲
Les interruptions sont traitÊes via la table de descripteurs d'interruption (Interrupt Descriptor Table - IDT). L'IDT dÊcrit un gestionnaire pour chaque interruption. Les interruptions sont numÊrotÊes (0 - 255) et le gestionnaire de l'interruption i est dÊfini à la position i dans la table. Il y a trois types diffÊrents de gestionnaires pour interruptions :
- gestionnaire de tâche ;
- gestionnaire d'interruption ;
- gestionnaire d'interception.
Les gestionnaires de tâches utilisent des fonctionnalitÊs spÊcifiques à la version Intel de x86, ils ne seront pas couverts ici (voir le manuel Intel, chapitre 6, pour plus d'information). La seule diffÊrence entre un gestionnaire d'interruption et un gestionnaire d'interception est que le gestionnaire d'interruption dÊsactive les interruptions, ce qui signifie que vous ne pouvez pas avoir une nouvelle interruption lorsque vous en gÊrez une. Dans ce livre, nous allons utiliser des gestionnaires d'interceptions et dÊsactiver manuellement les interruptions lorsque nous en avons besoin.
6-2. CrĂŠer un enregistrement dans l'IDT▲
Un enregistrement dans l'IDT pour un gestionnaire d'interruption se compose de 64 bits. Les 32 bits supÊrieurs sont prÊsentÊs dans la figure ci-dessous :
Bit : | 31 16 | 15 | 14 13 | 12 | 11 | 10 9 8 | 7 6 5 | 4 3 2 1 0 |
Contenu : | offset supÊrieur | P | DPL | 0 | D | 1 1 0 | 0 0 0 | rÊservÊ |Les 32 bits infÊrieurs sont prÊsentÊs dans la figure ci-dessous :
Bit : | 31 16 | 15 0 |
Contenu : |sÊlecteur de segment| offset infÊrieur |Une description pour chaque nom se trouve dans le tableau ci-dessous :
|
Nom |
Description |
|---|---|
|
offset supĂŠrieur |
Les 16 bits les plus ĂŠlevĂŠs de l'adresse de 32 bits dans le segment. |
|
offset infĂŠrieur |
Les 16 bits les plus bas de l'adresse de 32 bits dans le segment. |
|
p |
Si le gestionnaire est prĂŠsent en mĂŠmoire ou pas (1 = prĂŠsent, 0 = pas prĂŠsent). |
|
DPL |
Descripteur du niveau de privilège, le niveau de privilège à partir duquel le gestionnaire peut être appelÊ (0, 1, 2, 3). |
|
D |
Taille de la porte logique (1 = 32 bits, 0 = 16 bits). |
|
sĂŠlecteur de segment |
L'offset dans la GDT. |
|
r |
RĂŠservĂŠ. |
L'offset est un pointeur vers du code (de prÊfÊrence, une Êtiquette en code assembleur). Par exemple, pour crÊer une entrÊe pour un gestionnaire dont le code commence à 0xDEADBEEF et qui fonctionne en niveau de privilège 0 (donc en utilisant le même sÊlecteur de segment de code que le noyau), les deux octets suivants seront utilisÊs :
0xDEAD8E00
0x0008BEEFSi l'IDT est reprĂŠsentĂŠe comme un unsigned integer idt[512], alors pour enregistrer l'exemple ci-dessus en tant que gestionnaire pour interruption 0 (division par zĂŠro), le code suivant serait utilisĂŠÂ :
idt[0] = 0xDEAD8E00
idt[1] = 0x0008BEEFComme ĂŠcrit dans le chapitre ÂŤÂ Passage au CPassage au CÂ Âť, nous vous recommandons d'utiliser les structures compactĂŠes Ă la place des octets (ou entiers non signĂŠs), pour rendre le code plus lisible.
6-3. GĂŠrer une interruption▲
Lorsqu'une interruption se produit, le CPU va dÊposer certaines informations à propos de celle-ci sur la pile, puis recherchera le gestionnaire d'interruption appropriÊ dans l'IDT et sautera à celui-ci. La pile au moment de l'interruption va ressembler à ceci :
[esp + 12] eflags
[esp + 8] cs
[esp + 4] eip
[esp] error code?La raison de la prÊsence du point d'interrogation après error code est que les interruptions ne crÊent pas toutes un code d'erreur. Les interruptions spÊcifiques au CPU, qui mettent un code d'erreur sur la pile sont 8, 10, 11, 12, 13, 14 et 17. Le code d'erreur peut être utilisÊ par le gestionnaire d'interruption pour obtenir plus d'informations sur ce qui est arrivÊ. En outre, notez que le numÊro de l'interruption n'est pas dÊposÊ sur la pile. Nous pouvons dÊterminer quelle interruption a eu lieu uniquement en sachant quel code est exÊcutÊ - si le gestionnaire enregistrÊ pour l'interruption 17 est exÊcutÊ, alors c'est l'interruption 17 qui a eu lieu.
Une fois que le gestionnaire d'interruption a fini, il utilise l'instruction iret pour retourner. L'instruction iret s'attend Ă ce que la pile soit la mĂŞme que juste avant l'interruption (voir la figure ci-dessus). Par consĂŠquent, toutes les valeurs dĂŠposĂŠes sur la pile par le gestionnaire d'interruption doivent ĂŞtre enlevĂŠes. Avant de retourner, iret restaure eflags en ĂŠliminant la valeur de la pile, puis finalement saute Ă cs:eip, comme spĂŠcifiĂŠ par les valeurs sur la pile.
Le gestionnaire d'interruption doit être Êcrit en code assembleur, puisque tous les registres utilisÊs par les gestionnaires d'interruption doivent être prÊservÊs en les poussant sur la pile. Cela parce que le code qui a ÊtÊ interrompu ignore l'interruption et s'attendra donc à ce que ses registres ne changent pas. L'Êcriture de toute la logique du gestionnaire d'interruption en code assembleur serait fastidieuse. La crÊation en assembleur d'un gestionnaire qui sauvegarde les registres, appelle une fonction C, restaure les registres et finalement exÊcute iret est une bonne idÊe !
Le gestionnaire C devrait obtenir comme arguments l'Êtat des registres, l'Êtat de la pile et le numÊro de l'interruption. Les dÊfinitions suivantes peuvent par exemple être utilisÊes :
struct cpu_state {
unsigned int eax;
unsigned int ebx;
unsigned int ecx;
.
.
.
unsigned int esp;
} __attribute__((packed));
struct stack_state {
unsigned int error_code;
unsigned int eip;
unsigned int cs;
unsigned int eflags;
} __attribute__((packed));
void interrupt_handler(struct cpu_state cpu, struct stack_state stack, unsigned int interrupt);6-4. CrĂŠer un gestionnaire d'interruption gĂŠnĂŠrique▲
Puisque le CPU ne dÊpose pas sur la pile le numÊro de l'interruption, l'Êcriture d'un gestionnaire d'interruption gÊnÊrique est un peu difficile. Cette section utilisera des macros pour montrer comment faire. L'Êcriture d'une version pour chaque interruption est fastidieuse, il est prÊfÊrable d'utiliser la fonctionnalitÊ de macro de NASM(33). Et puisque toutes les interruptions ne produisent pas un code d'erreur, la valeur 0 sera ajoutÊe comme  code d'erreur  pour les interruptions sans aucun code d'erreur. Le code suivant montre un exemple de la façon dont cela peut être fait :
%macro no_error_code_interrupt_handler %1
global interrupt_handler_%1
interrupt_handler_%1:
push dword 0 ; met 0 comme code d'erreur
push dword %1 ; met le nombre de l'interruption
jmp common_interrupt_handler ; saute au gestionnaire gĂŠnĂŠrique
%endmacro
%macro error_code_interrupt_handler %1
global interrupt_handler_%1
interrupt_handler_%1:
push dword %1 ; met le nombre de l'interruption
jmp common_interrupt_handler ; saute au gestionnaire gĂŠnĂŠrique
%endmacro
common_interrupt_handler: ; les parties communes du gestionnaire d'interruption gĂŠnĂŠrique
; sauvegarder les registres
push eax
push ebx
.
.
.
push ebp
; appeler la fonction C
call interrupt_handler
; restaurer les registres
pop ebp
.
.
.
pop ebx
pop eax
; restaurer le esp
add esp, 8
; retourner au code qui a ĂŠtĂŠ interrompu
iret
no_error_code_interrupt_handler 0 ; crĂŠer gestionnaire pour interruption 0
no_error_code_interrupt_handler 1 ; crĂŠer gestionnaire pour interruption 1
.
.
.
error_code_handler 7 ; crĂŠer gestionnaire pour interruption 7
.
.
.Le common_interrupt_handler effectue les opÊrations suivantes :
- sauvegarde les registres sur la pile ;
- appelle la fonction C interrupt_handler ;
- rÊcupère les registres de la pile ;
- ajoute 8 Ă esp (Ă cause du code d'erreur et du numĂŠro de l'interruption dĂŠposĂŠ plus tĂ´t)Â ;
- exĂŠcute iret pour revenir au code interrompu.
Comme les macros dĂŠclarent des ĂŠtiquettes globales, les adresses des gestionnaires d'interruption peuvent ĂŞtre accessibles Ă partir du code C ou du code assembleur lors de la crĂŠation de l'IDT.
6-5. Charger l'IDT▲
L'IDT est chargĂŠe avec l'instruction en assembleur lidt, qui prend l'adresse du premier ĂŠlĂŠment dans le tableau. Le plus simple est d'incorporer cette instruction dans du code CÂ :
global load_idt
; load_idt - Charge la table de descripteurs d'interruptions (IDT).
; pile : [esp + 4] l'adresse du premier enregistrement dans l'IDT
; [esp ] l'adresse de retour
load_idt:
mov eax, [esp+4] ; charge l'adresse de l'IDT dans le registre eax
lidt eax ; charge l'IDT
ret ; retourne Ă la fonction appelante6-6. ContrĂ´leur d'interruption programmable▲
Pour commencer à utiliser les interruptions matÊrielles, vous devez d'abord configurer le contrôleur d'interruption programmable (Programmable Interrupt Controller - PIC). Le PIC rend possible le mappage des signaux provenant du matÊriel vers des interruptions. Les raisons pour configurer le PIC sont :
- modifier le mappage des interruptions. Le PIC utilise par dÊfaut les interruptions 0-15 pour les interruptions matÊrielles, ce qui entre en conflit avec les interruptions du CPU. Par consÊquent, les interruptions PIC doivent être rÊaffectÊes à un autre intervalle ;
- sÊlectionner les interruptions à recevoir. Vous ne voulez probablement pas recevoir des interruptions de tous les pÊriphÊriques, puisque de toute façon vous ne disposez pas de code qui gère ces interruptions ;
- configurer le mode correct pour le PIC.
Au dĂŠbut, il n'y avait qu'un seul PIC (PIC 1) et huit interruptions. Comme on a ajoutĂŠ plus de matĂŠriel, 8 interruptions ne suffisaient pas. La solution retenue a ĂŠtĂŠ d'enchaĂŽner un autre PIC (PIC 2) au premier PIC (voir l'interruption 2 sur PIC 1).
Les interruptions matÊrielles sont prÊsentÊes dans le tableau ci-dessous :
|
PIC 1 |
MatĂŠriel |
PIC 2 |
MatĂŠriel |
|---|---|---|---|
|
0 |
Timer |
8 |
Horloge temps rĂŠel |
|
1 |
Clavier |
9 |
E/S gĂŠnĂŠrales |
|
2 |
PIC 2 |
10 |
E/S gĂŠnĂŠrales |
|
3 |
COM 2 |
11 |
E/S gĂŠnĂŠrales |
|
4 |
COM 1 |
12 |
E/S gĂŠnĂŠrales |
|
5 |
LPT 2 |
13 |
Coprocesseur |
|
6 |
Disquette |
14 |
Bus IDE |
|
7 |
LPT 1 |
15 |
Bus IDE |
Un excellent tutoriel pour configurer le PIC peut ĂŞtre trouvĂŠ sur le site web de SigOPS(34). Nous ne rĂŠpĂŠterons pas cette information ici.
La rĂŠception de chaque interruption envoyĂŠe par le PIC doit ĂŞtre confirmĂŠe, c'est-Ă -dire qu'il faut envoyer au PIC un message confirmant que l'interruption a ĂŠtĂŠ gĂŠrĂŠe. Si cela n'est pas fait, le PIC ne gĂŠnĂŠrera aucune autre interruption.
La confirmation de rĂŠception d'une interruption se fait par l'envoi de l'octet 0x20 au PIC qui a dĂŠclenchĂŠ l'interruption. Mettre en Ĺuvre une fonction de pic_acknowledge peut donc se faire comme suit :
#include "io.h"
#define PIC1_PORT_A 0x20
#define PIC2_PORT_A 0xA0
/* Le mappage des interruptions PIC a ĂŠtĂŠ modifiĂŠ */
#define PIC1_START_INTERRUPT 0x20
#define PIC2_START_INTERRUPT 0x28
#define PIC2_END_INTERRUPT PIC2_START_INTERRUPT + 7
#define PIC_ACK 0x20
/** pic_acknowledge:
* Confirme la rĂŠception d'une interruption Ă partir de PIC 1 ou PIC 2.
*
* @param num Le numĂŠro de l'interruption
*/
void pic_acknowledge(unsigned integer interruption)
{
if (interruption < PIC1_START_INTERRUPT || interruption > PIC2_END_INTERRUPT) {
return;
}
if (interruption < PIC2_START_INTERRUPT) {
outb(PIC1_PORT_A, PIC_ACK);
} else {
outb(PIC2_PORT_A, PIC_ACK);
}
}6-7. Lire la saisie clavier▲
Le clavier ne gÊnère pas de caractères ASCII, il gÊnère des codes de balayage. Un code de balayage reprÊsente un bouton - les deux actions, appuyer et relâcher. Le code de balayage reprÊsentant le bouton juste enfoncÊ peut être lu à partir du port de donnÊes d'E/S du clavier, dont l'adresse 0x60. La façon de le faire est prÊsentÊe dans l'exemple suivant :
#include "io.h"
#define KBD_DATA_PORT 0x60
/** read_scan_code :
* Lit un code de balayage Ă partir du clavier
*
* @return Le code de balayage (PAS un caractère ASCII !)
*/
unsigned char read_scan_code(void)
{
return inb(KBD_DATA_PORT);
}L'Êtape suivante est d'Êcrire une fonction qui traduit un code de balayage en caractère ASCII correspondant. Si vous souhaitez mapper les codes de balayage vers des caractères ASCII comme on le fait sur un clavier amÊricain, alors Andries Brouwer a Êcrit un excellent tutoriel(35) à ce sujet.
Comme l'interruption clavier est levĂŠe par le PIC, n'oubliez pas que vous devez appeler pic_acknowledge Ă la fin du gestionnaire d'interruption du clavier. En outre, le clavier ne vous enverra aucune autre interruption jusqu'Ă ce que vous lisiez le code de balayage du clavier.
6-8. Lectures complĂŠmentaires▲
- Le wiki de OSDev contient une page excellente sur les interruptions, http://wiki.osdev.org/Interrupts
- Le chapitre 6 du manuel Intel 3a (33) dĂŠcrit tout ce qu'il y a Ă savoir sur les interruptions.
7. La route vers le mode utilisateur▲
Maintenant que le noyau dÊmarre, affiche à l'Êcran et lit à partir du clavier - qu'est-ce qu'on fait ? Habituellement, un noyau n'est pas censÊ s'occuper lui-même de la logique de l'application, mais laisse cela aux applications. Le noyau crÊe les abstractions adÊquates (pour la mÊmoire, les fichiers, les pÊriphÊriques) afin de rendre plus facile le dÊveloppement d'applications, effectue des tâches pour le compte des applications (appels système) et planifie des processusMultitâche.
Le mode utilisateur, contrairement au mode noyau, est l'environnement dans lequel s'exĂŠcutent les programmes de l'utilisateur. Cet environnement est moins privilĂŠgiĂŠ que le noyau, et empĂŞchera les programmes (mal ĂŠcrits) de l'utilisateur de perturber d'autres programmes ou le noyau. Les noyaux mal ĂŠcrits sont libres de mettre la pagaille oĂš ils veulent.
Il y a tout un chemin Ă parcourir jusqu'Ă ce que l'OS crĂŠĂŠ dans ce livre arrive Ă exĂŠcuter des programmes en mode utilisateur, mais ce chapitre montrera comment exĂŠcuter facilement un petit programme en mode noyau.
7-1. Chargement d'un programme externe▲
D'oÚ pouvons-nous obtenir le programme externe ? D'une façon ou d'une autre, nous avons besoin de charger dans la mÊmoire le code que nous voulons exÊcuter. Les systèmes d'exploitation plus ÊvoluÊs ont gÊnÊralement des pilotes et des systèmes de fichiers qui leur permettent de charger le logiciel à partir d'un lecteur de CD-ROM, un disque dur ou d'autres mÊdias persistants.
Au lieu de crÊer tous ces pilotes et systèmes de fichiers, nous allons utiliser la fonctionnalitÊ modules de GRUB pour charger le programme.
7-1-1. Les modules GRUB▲
GRUB peut charger des fichiers arbitraires dans la mÊmoire de l'image ISO, et ces fichiers sont gÊnÊralement appelÊs modules. Pour faire en sorte que GRUB charge un module, Êditez le fichier iso/boot/grub/menu.lst et ajoutez la ligne suivante à la fin du fichier :
module /modules/programCrÊez ensuite le dossier iso/modules :
mkdir -p iso/modulesL'application program sera crĂŠĂŠe plus loin dans ce chapitre.
Le code qui appelle kmain doit ĂŞtre mis Ă jour pour transmettre Ă kmain des informations Ă propos de l'endroit oĂš il peut trouver les modules. Nous voulons aussi dire Ă GRUB qu'il doit aligner tous les modules sur les limites de page lors de leur chargement (voir le chapitre PaginationPagination pour plus de dĂŠtails au sujet de l'alignement de la page).
Pour dire à GRUB comment charger nos modules, il faut mettre à jour l'en-tête multiamorces - les premiers octets du noyau - comme suit :
; dans le fichier `loader.s`
NOMBRE_MAGIQUE equ 0x1BADB002 ; dĂŠfinir la constante nombre magique
ALIGN_MODULES equ 0x00000001 ; dire Ă GRUB d'aligner les modules
; calculer la somme de contrĂ´le CHECKSUM (toutes les options + somme de contrĂ´le doit ĂŞtre ĂŠgal Ă 0)
CHECKSUM equ -(NOMBRE_MAGIQUE + ALIGN_MODULES)
section .text: ; dĂŠbut de la section de texte (code)
align 4 ; le code doit ĂŞtre alignĂŠ sur 4 octets
dd NOMBRE_MAGIQUE ; ĂŠcrit le nombre magique
dd ALIGN_MODULES ; ĂŠcrit l'instruction d'alignement des modules
dd CHECKSUM ; ĂŠcrit la somme de contrĂ´leGRUB stocke ĂŠgalement un pointeur vers une struct dans le registre ebx qui, entre autres choses, dĂŠcrit Ă quelles adresses sont chargĂŠs les modules. Par consĂŠquent, vous voulez probablement pousser ebx sur la pile avant d'appeler kmain, pour en faire un argument pour kmain.
7-2. ExĂŠcuter un programme▲
7-2-1. Un programme très simple▲
Un programme Êcrit à ce stade ne peut effectuer que quelques actions. Par consÊquent, un programme très court qui Êcrit une valeur dans un registre suffit comme programme de test. Interrompre Bochs après un certain temps et vÊrifier en regardant dans le journal de Bochs que le registre contient le nombre correct, permettra de vÊrifier que le programme a ÊtÊ exÊcutÊ. Ci-dessous, un exemple d'un tel programme court :
; affecter Ă eax un nombre facile Ă distinguer, Ă lire ensuite dans le journal
mov eax, 0xDEADBEEF
; entrer dans la boucle infinie, rien de plus Ă faire
; $ signifie "dĂŠbut de ligne", c.-Ă -d la mĂŞme instruction
jmp $7-2-2. Compiler▲
Puisque notre noyau ne peut pas analyser les formats exÊcutables avancÊs, nous avons besoin de compiler le code dans un fichier binaire plat. NASM peut le faire avec l'option -f :
nasm -f bin program.s -o programCeci est tout ce qu'il faut. Vous devez maintenant dĂŠplacer le programme de fichier dans le dossier iso/modules.
7-2-3. Trouver le programme en mĂŠmoire▲
Avant de passer au programme, nous devons trouver l'emplacement de la mÊmoire oÚ il rÊside. En supposant que le contenu de epx est passÊ comme argument à kmain, nous pouvons faire cela entièrement à partir du code C.
Le pointeur dans ebx pointe vers une structure multiamorces (19). TĂŠlĂŠchargez le fichier multiboot.h, qui dĂŠcrit la structure, Ă http://www.gnu.org/software/grub/manual/multiboot/html_node/multiboot.h.html.
Le pointeur passÊ à kmain dans le registre ebx peut être converti en un pointeur multiboot_info_t. L'adresse du premier module se trouve sur mods_addr. Le code suivant montre un exemple :
int kmain(/* arguments additionnels */ unsigned int ebx)
{
multiboot_info_t *mbinfo = (multiboot_info_t *) ebx;
unsigned int adresse_du_module = mbinfo->mods_addr;
}Toutefois, avant de simplement suivre aveuglĂŠment le pointeur, vous devez vĂŠrifier que le module a ĂŠtĂŠ chargĂŠ correctement par GRUB. Cela peut ĂŞtre fait en vĂŠrifiant le champ flags de la structure de multiboot_info_t. Vous devriez ĂŠgalement vĂŠrifier le champ mods_count, pour vous assurer que sa valeur est exactement 1. Pour plus de dĂŠtails sur la structure multiamorces, consultez sa documentation (19).
7-2-4. Sauter au code▲
La seule chose qui reste à faire est de sauter au code chargÊ par GRUB. Puisqu'il est plus facile d'analyser la structure multiamorces en code C qu'en assembleur, il est plus pratique d'appeler le code à partir du code C (cela peut bien sÝr être fait aussi avec jmp ou call en code assembleur). Le code C pourrait ressembler à ceci :
typedef void (*call_module_t)(void);
/* ... */
call_module_t start_program = (call_module_t) adresse_du_module;
start_program();
/* nous n'arrivons jamais ici, sauf si le code du module retourne */Si nous lançons le noyau, attendons jusqu'à ce qu'il s'exÊcute et entre dans la boucle infinie du programme, puis arrêtons Bochs, nous devrions voir via le journal de Bochs la valeur 0xDEADBEEF dans le registre eax. Nous avons lancÊ avec succès un programme dans notre OS !
7-3. Le dĂŠbut du mode utilisateur▲
Le programme que nous avons Êcrit s'exÊcute maintenant au même niveau de privilège que le noyau - nous y sommes juste entrÊs d'une manière un peu particulière. Pour permettre aux applications de s'exÊcuter à un niveau de privilège diffÊrent, nous devrons, en plus de la segmentationSegmentation, nous occuper de la paginationPagination et de l'allocation de trame de pageAllocation de trames de page.
Cela reprĂŠsente pas mal de travail et de dĂŠtails techniques Ă traverser, mais d'ici quelques chapitres vous aurez des programmes fonctionnant en mode utilisateur.
8. Une courte introduction Ă la mĂŠmoire virtuelle▲
La mĂŠmoire virtuelle est une abstraction de la mĂŠmoire physique. GĂŠnĂŠralement, le but de la mĂŠmoire virtuelle est de simplifier le dĂŠveloppement d'applications et de mettre Ă la disposition des processus plus de mĂŠmoire qu'il n'en existe rĂŠellement physiquement dans la machine. Aussi, pour raisons de sĂŠcuritĂŠ, nous ne voulons pas que les applications touchent Ă la mĂŠmoire allouĂŠe au noyau ou aux autres applications.
Dans l'architecture x86, la mĂŠmoire virtuelle peut ĂŞtre rĂŠalisĂŠe de deux façons : par segmentation et par pagination. La pagination est de loin la technique la plus courante et la plus polyvalente, et nous allons la mettre en Ĺuvre dans le chapitre suivant. Certaines utilisations de la segmentation sont encore nĂŠcessaires pour permettre au code de s'exĂŠcuter Ă diffĂŠrents niveaux de privilèges.
La gestion de la mÊmoire reprÊsente une grande partie de ce qu'un système d'exploitation fait. Les chapitres PaginationPagination et Allocation de trame de pageAllocation de trames de page traitent de cela.
La segmentation et la pagination sont dĂŠcrites dans le manuel Intel (33), chapitres 3 et 4.
8-1. MĂŠmoire virtuelle grâce Ă la segmentation ?▲
Vous pourriez vous passer complètement de la pagination et utiliser juste la segmentation pour la mÊmoire virtuelle. Chaque processus en mode utilisateur obtiendrait son propre segment, avec l'adresse de base et la limite correctement mises en place. De cette façon, aucun processus ne peut voir la mÊmoire d'un autre processus. Dans ce cas-là , un problème est que la mÊmoire physique pour un processus doit être contiguÍ (ou du moins, c'est très pratique si elle l'est). Soit nous devons savoir à l'avance combien de mÊmoire utilisera le programme (c'est peu probable), soit nous pouvons dÊplacer les segments de mÊmoire, lorsque la limite est atteinte, dans des endroits oÚ ils peuvent croÎtre (ce qui est coÝteux, entraÎne une fragmentation et peut dÊboucher sur une erreur  mÊmoire insuffisante  même s'il y a assez de mÊmoire est disponible). La pagination rÊsout ces problèmes.
Il est intÊressant de noter que dans x86_64 (la version 64 bits de l'architecture x86), la segmentation est presque complètement ÊliminÊe.
8-2. Lectures complĂŠmentaires▲
- Sur LWN.net il y a un article sur la mÊmoire virtuelle : http://lwn.net/Articles/253361/
- Gustavo Duarte a Êcrit Êgalement un article sur la mÊmoire virtuelle : http://duartes.org/gustavo/blog/post/memory-translation-and-segmentation
9. Pagination▲
La segmentation traduit une adresse logique en une adresse linÊaire. La pagination traduit ces adresses linÊaires sur l'espace d'adressage physique, et dÊtermine les droits d'accès et comment la mÊmoire doit être mise en cache.
9-1. Pourquoi pagination ?▲
La pagination est la technique la plus couramment utilisÊe dans l'architecture x86 pour permettre la mÊmoire virtuelle. La mÊmoire virtuelle par le biais de la pagination signifie que chaque processus aura l'impression que la plage de mÊmoire disponible est 0x00000000 - 0xFFFFFFFF, même si la taille rÊelle de la mÊmoire est peut-être bien moindre. Cela signifie Êgalement que lorsqu'un processus accède à un octet de mÊmoire, il utilisera une adresse virtuelle (linÊaire) au lieu d'une adresse physique. Le code dans le processus de l'utilisateur ne remarquera aucune diffÊrence (sauf pour les dÊlais d'exÊcution). L'adresse linÊaire est traduite en une adresse physique par la MMU et la table des pages. Si l'adresse virtuelle n'est pas mappÊe à une adresse physique, le processeur dÊclenchera une interruption de dÊfaut de page.
La pagination est facultative et certains systèmes d'exploitation n'en font pas usage. Mais si nous voulons marquer certaines zones de mÊmoire comme accessibles seulement à l'exÊcution du code ayant un certain niveau de privilège (pour être en mesure d'avoir des processus s'exÊcutant à diffÊrents niveaux de privilège), la pagination est la façon la plus ÊlÊgante de le faire.
9-2. Pagination en x86▲
La pagination en x86 (le chapitre 4 du manuel Intel) se compose d'une table rĂŠpertoire de page (page directory, ou PDT) qui peut contenir des rĂŠfĂŠrences vers 1024 tables des pages (PT), dont chacune peut pointer vers 1024 sections de mĂŠmoire physique appelĂŠes trames de page (PF). Chaque trame de page a une taille de 4096 octets. Dans une adresse virtuelle (linĂŠaire), les 10 bits de poids fort spĂŠcifient le dĂŠcalage d'une entrĂŠe de rĂŠpertoire de page (page directory entry - PDE) dans le PDT courant, les 10 bits suivants - le dĂŠcalage d'une entrĂŠe de table des pages (page table entry - PTE) dans la table des pages pointĂŠe par ce PDE. Les 12 bits de poids faible de l'adresse reprĂŠsentent le dĂŠcalage dans le cadre de page Ă traiter.
Tous les rĂŠpertoires de pages, tables de pages et trames de pages doivent ĂŞtre alignĂŠs sur des adresses de 4096 octets. Cela permet d'adresser une PDT, PT ou PF avec seulement les 20 bits les plus forts d'une adresse de 32 bits, puisque les 12 bits infĂŠrieurs doivent ĂŞtre nuls.
La structure des PDE et celle des PTE sont très semblables, chacune ayant 32 bits (4 octets), oÚ les 20 bits les plus hauts pointent vers une PTE ou PF, et les 12 bits les plus faibles contrôlent les droits d'accès et autres configurations. 4 octets fois 1024 est Êgal à 4096 octets, donc un rÊpertoire de page et une table de pages rentrent tous les deux dans une trame de page.
La traduction des adresses linĂŠaires en adresses physiques est dĂŠcrite dans la figure ci-dessous.
Bien que les pages aient normalement 4096 octets, il est ĂŠgalement possible d'utiliser des pages de 4 Mo. Une PDE pointe ensuite directement vers une trame de page de 4 Mo, qui doit ĂŞtre alignĂŠe sur une limite d'adresse de 4 Mo. La traduction d'adresse est presque la mĂŞme que sur la figure, avec juste l'ĂŠtape de table de page supprimĂŠe. Il est possible de mĂŠlanger des pages de 4 Mo et de 4 ko.
Les 20 bits pointant vers la PDT courante sont stockĂŠs dans le registre cr3. Les 12 bits infĂŠrieurs de cr3 sont utilisĂŠs pour la configuration.
Pour plus de dÊtails sur les structures des pages, voir le chapitre 4 dans le manuel Intel (33). Les bits les plus intÊressants sont U/S, qui dÊterminent quels niveaux de privilèges peuvent accÊder à cette page (PL0 ou PL3), et R/W, ce qui rend la mÊmoire dans la page disponible en lecture-Êcriture ou en lecture seule.
9-2-1. Pagination d'identitĂŠ▲
Le type le plus simple de pagination, appelĂŠ pagination d'identitĂŠ, est quand nous mappons chaque adresse virtuelle vers la mĂŞme adresse physique. Cela peut ĂŞtre fait au moment de la compilation en crĂŠant un rĂŠpertoire de page oĂš chaque entrĂŠe pointe vers sa trame de 4 Mo correspondante. En NASM, cela peut ĂŞtre fait avec des macros et des commandes (%rep, times et dd). Cela peut bien sĂťr ĂŞtre fait ĂŠgalement au moment de l'exĂŠcution, en utilisant des instructions ordinaires de code assembleur.
9-2-2. Activer la pagination▲
La pagination est activÊe en Êcrivant d'abord l'adresse d'un rÊpertoire de page dans cr3, puis en modifiant le bit 31 (le bit PG,  activer la pagination ) de cr0 à 1. Pour utiliser des pages de 4 Mo, dÊfinissez le bit PSE (Page Size Extensions,  extensions de taille de la page , bit 4) dans cr4. Le code assembleur suivant montre un exemple :
; eax contient l'adresse du rĂŠpertoire de la page
mov cr3, eax
mov ebx, cr4 ; lire la valeur courante de cr4
or ebx, 0x00000010 ; dĂŠfinir PSE
mov cr4, ebx ; mettre Ă jour cr4
mov ebx, cr0 ; lire la valeur courante de cr0
or ebx, 0x80000000 ; dĂŠfinir PG
mov cr0, ebx ; mettre Ă jour cr0
; la pagination est maintenant activĂŠe9-2-3. Quelques dĂŠtails▲
Il est important de noter que toutes les adresses dans le rĂŠpertoire de page, dans les tables de page et dans cr3 doivent ĂŞtre des adresses physiques des structures, jamais virtuelles. Cela sera plus pertinent dans les sections suivantes, oĂš nous mettrons Ă jour dynamiquement les structures de pagination (voir le chapitre La route vers le mode utilisateurLa route vers le mode utilisateur).
Une instruction utile lors d'une mise Ă jour d'une PDT ou d'une PT est invlpg. Elle annule l'entrĂŠe d'une adresse virtuelle dans le Translate Lookaside Buffer (TLB). Le TLB est un cache pour les adresses traduites, qui effectue la correspondance entre des adresses physiques et virtuelles. Cela est nĂŠcessaire uniquement lors de la modification d'une PDE ou PTE qui a dĂŠjĂ ĂŠtĂŠ mappĂŠe vers autre chose. Si la PDE ou la PTE avait dĂŠjĂ ĂŠtĂŠ marquĂŠe comme non prĂŠsente (le bit 0 a ĂŠtĂŠ mis Ă 0), l'exĂŠcution de invlpg est inutile. En modifiant la valeur de cr3, toutes les entrĂŠes du TLB seront invalidĂŠes.
Voici un exemple d'invalidation d'une entrĂŠe du TLBÂ :
; rend invalide toute rĂŠfĂŠrence dans le TLB vers l'adresse virtuelle 0
invlpg [0]9-3. Pagination et noyau▲
Cette section dĂŠcrira comment la pagination affecte le noyau de l'OS. Nous vous encourageons Ă gĂŠrer votre OS en utilisant la pagination d'identitĂŠ avant d'essayer de mettre en Ĺuvre une configuration de pagination plus avancĂŠe, car il peut ĂŞtre difficile de dĂŠboguer une table de page dysfonctionnelle mise en place en code assembleur.
9-3-1. Raisons de ne pas utiliser le mappage d'identitĂŠ pour le noyau▲
Si le noyau est placÊ au dÊbut de l'espace d'adressage virtuel - c'est-à -dire que l'espace d'adressage virtuel (0x00000000, "taille du noyau") mappe vers l'emplacement du noyau en mÊmoire - il y aura des problèmes lors de l'Êdition des liens du code du processus en mode utilisateur. Normalement, pendant l'Êdition des liens, l'Êditeur de liens suppose que le code sera chargÊ dans la mÊmoire à la position 0x00000000. Par consÊquent, lors de la rÊsolution des rÊfÊrences absolues, 0x00000000 sera l'adresse de base pour calculer la position exacte. Mais si le noyau est mappÊ sur l'espace d'adressage virtuel (0x00000000, "taille du noyau"), le processus en mode utilisateur ne peut pas être chargÊ à l'adresse virtuelle 0x00000000 - il doit être placÊ ailleurs. Par consÊquent, l'hypothèse de l'Êditeur de liens que le processus en mode utilisateur est chargÊ en mÊmoire à la position 0x00000000 est erronÊe. Ce problème peut être corrigÊ en utilisant un script, qui dit à l'Êditeur de liens de prendre une adresse de dÊpart diffÊrente, mais c'est une solution très lourde pour les utilisateurs du système d'exploitation.
Cela suppose Êgalement que nous voulons que le noyau fasse partie de l'espace d'adressage du processus en mode utilisateur. Comme nous le verrons plus tard, c'est une fonctionnalitÊ intÊressante, puisque pendant les appels système, nous ne devons modifier aucune structure de pagination pour avoir accès au code et aux donnÊes du noyau. L'accès aux pages du noyau exigera bien sÝr le niveau de privilège 0, pour Êviter qu'un processus utilisateur lise ou Êcrive la mÊmoire du noyau.
9-3-2. L'adresse virtuelle pour le noyau▲
Le noyau doit être placÊ de prÊfÊrence à une adresse très ÊlevÊe de mÊmoire virtuelle, par exemple 0xC0000000 (3 Go). Il est peu probable que le processus en mode utilisateur ait une taille de 3 Go, et c'est la seule façon qu'il aurait d'entrer en conflit avec le noyau. Lorsque le noyau utilise des adresses virtuelles à 3 Go et supÊrieures, on parle d'un noyau mis en moitiÊ supÊrieure. 0xC0000000 est juste un exemple, le noyau peut être placÊ à une autre adresse supÊrieure à 0 pour obtenir les mêmes avantages. Le choix de la bonne adresse dÊpend de la quantitÊ de mÊmoire virtuelle qui doit être disponible pour le noyau (c'est plus facile quand toute la mÊmoire en dessus de l'adresse virtuelle du noyau appartient au noyau) et de la quantitÊ de mÊmoire virtuelle qui doit être disponible pour le processus.
Si le processus en mode utilisateur est supĂŠrieur Ă 3Â Go, certaines pages devront ĂŞtre swappĂŠes par le noyau. Ce livre ne couvre pas le swapping de pages.
9-3-3. Placer le noyau Ă 0xC0000000▲
Pour commencer, il est prÊfÊrable de placer le noyau plutôt à 0xC0100000 qu'à 0xC0000000, puisque cela permet de mapper (0x00000000, 0x00100000) à (0xC0000000, 0xC0100000). De cette façon, l'ensemble de la plage de mÊmoire (0x00000000, "taille du noyau") est mappÊ vers la gamme (0xC0000000, 0xC0000000 + "taille du noyau").
Placer le noyau Ă 0xC0100000 n'est pas difficile, mais exige une certaine rĂŠflexion, car nous avons une fois de plus un problème d'ĂŠdition de liens. Lorsque l'ĂŠditeur de liens rĂŠsout toutes les rĂŠfĂŠrences absolues dans le noyau, il va supposer que notre noyau est chargĂŠ Ă l'emplacement 0x00100000 de la mĂŠmoire physique et pas Ă 0x00000000, puisque le dĂŠplacement est utilisĂŠ dans le script de l'ĂŠditeur de liens (voir la section Ăditer les liens du noyauĂditer les liens du noyau). Cependant, nous voulons que les sauts soient rĂŠsolus en utilisant comme adresse de base 0xC0100000, car sinon un saut de noyau sautera directement dans le code du processus en mode utilisateur (rappelez-vous que le processus en mode utilisateur est chargĂŠ Ă l'emplacement 0x00000000 de la mĂŠmoire virtuelle).
Cependant, nous ne pouvons pas simplement dire Ă l'ĂŠditeur de liens de supposer que le noyau dĂŠmarre (est chargĂŠ) Ă 0xC01000000, car nous voulons qu'il soit chargĂŠ Ă l'adresse physique 0x00100000. La raison d'avoir le noyau chargĂŠ Ă 1 Mo est parce qu'il ne peut pas ĂŞtre chargĂŠ Ă 0x00000000, puisque le code de BIOS et de GRUB est chargĂŠ en dessous de 1 Mo. En outre, nous ne pouvons pas supposer que nous pouvons charger le noyau Ă 0xC0100000, puisque la machine pourrait ne pas avoir 3 Go de mĂŠmoire physique.
Cela peut ĂŞtre rĂŠsolu en utilisant Ă la fois le dĂŠplacement (.=0xC0100000) et l'instruction AT dans le script de l'ĂŠditeur de liens. Le dĂŠplacement prĂŠcise que les rĂŠfĂŠrences de mĂŠmoire non relatives doivent utiliser l'adresse de relocalisation en tant que base pour les calculs d'adresses. AT spĂŠcifie l'endroit oĂš le noyau doit ĂŞtre chargĂŠ en mĂŠmoire. Le dĂŠplacement est effectuĂŠ par la fonction GNU ld(36) au moment de la liaison, l'adresse de chargement spĂŠcifiĂŠe par AT est gĂŠrĂŠe par GRUB lors du chargement du noyau, et fait partie du format ELF (18).
9-3-4. Script d'ĂŠditeur de liens de la moitiĂŠ supĂŠrieure▲
Nous pouvons modifier le premier script d'ĂŠditeur de liensĂditer les liens du noyau pour implĂŠmenter ceci :
ENTRY(loader) /* le nom du symbole en entrĂŠe */
. = 0xC0100000 /* le code devrait ĂŞtre be relocalisĂŠ Ă 3Go + 1Mo */
/* alignement Ă 4 ko et chargement Ă 1 Mo */
.text ALIGN (0x1000) : AT(ADDR(.text)-0xC0000000)
{
*(.text) /* toutes les sections texte, de tous les fichiers */
}
/* alignement Ă 4 ko et chargement Ă 1 Mo + . */
.rodata ALIGN (0x1000) : AT(ADDR(.text)-0xC0000000)
{
*(.rodata*) /* toutes les sections de donnĂŠes en lecture seule, de tous les fichiers */
}
/* alignement Ă 4 ko et chargement Ă 1 Mo + . */
.data ALIGN (0x1000) : AT(ADDR(.text)-0xC0000000)
{
*(.data) /* toutes les sections de donnĂŠes, de tous les fichiers */
}
/* alignement Ă 4 ko et chargement Ă 1 MB + . */
.bss ALIGN (0x1000) : AT(ADDR(.text)-0xC0000000)
{
*(COMMON) /* toutes les sections COMMON, de tous les fichiers */
*(.bss) /* toutes les sections bss, de tous les fichiers */
}9-3-5. AccĂŠder Ă la moitiĂŠ supĂŠrieure▲
Lorsque GRUB saute au code du noyau, il n'y a aucune table de pagination. Par consÊquent, toutes les rÊfÊrences à 0xC0100000 + x ne seront pas mappÊes vers l'adresse physique correcte, ce qui provoquera au mieux une exception de protection gÊnÊrale (general protection exception - GPE), sinon (si l'ordinateur possède plus de 3 Go de mÊmoire) l'ordinateur plantera tout simplement.
Par consÊquent, il faut utiliser du code assembleur qui n'utilise aucun saut relatif ou adressage relatif de la mÊmoire pour :
- mettre en place une table de pages ;
- ajouter le mappage d'identitÊ pour les 4 premiers Mo de l'espace d'adressage virtuel ;
- ajouter une entrĂŠe pour 0xC0100000 qui correspond Ă 0x0010000.
Si nous omettons le mappage d'identitÊ pour les 4 premiers Mo, le processeur gÊnÊrera une faute de page immÊdiatement après l'activation de la pagination, en essayant de chercher dans la mÊmoire la prochaine instruction. Après la crÊation de la table, un saut à une Êtiquette peut être fait pour faire pointer eip vers une adresse virtuelle dans la moitiÊ supÊrieure :
; code assembleur s'exĂŠcutant alentour de 0x00100000
; active la pagination tant pour l'emplacement rĂŠel du noyau
; que pour son adresse virtuelle dans la moitiĂŠ supĂŠrieure
lea ebx, [higher_half] ; charge l'adresse de l'ĂŠtiquette dans ebx
jmp ebx ; saute Ă l'ĂŠtiquette
higher_half:
; le code ici s'exĂŠcute dans le noyau de la moitiĂŠ supĂŠrieure
; eip est plus large que 0xC0000000
; peut continuer l'initialisation du noyau, appels au code C, etc.Le registre eip pointera maintenant vers un emplacement en mÊmoire quelque part juste après 0xC0100000 - tout le code peut maintenant s'exÊcuter comme s'il Êtait situÊ à 0xC0100000, la moitiÊ supÊrieure. L'entrÊe qui mappe les 4 premiers Mo de mÊmoire virtuelle aux 4 premiers Mo de mÊmoire physique peut maintenant être retirÊe de la table de pages et son entrÊe correspondante dans le TLB peut être invalidÊe avec invlpg [0].
9-3-6. ExĂŠcuter dans la moitiĂŠ supĂŠrieure▲
Il y a encore quelques dĂŠtails Ă rĂŠgler lors de l'utilisation d'un noyau en moitiĂŠ supĂŠrieure. Nous devons ĂŞtre prudents en utilisant les E/S mappĂŠes en mĂŠmoire qui utilisent des emplacements spĂŠcifiques de mĂŠmoire. Par exemple, le tampon de trame est situĂŠ Ă 0x000B8000, mais comme l'entrĂŠe 0x000B8000 il n'existe plus dans la table de pages, l'adresse 0xC00B8000 doit ĂŞtre utilisĂŠe, puisque l'adresse virtuelle 0xC0000000 mappe vers l'adresse physique 0x00000000.
Toute rĂŠfĂŠrence explicite Ă des adresses au sein de la structure multiamorce doit ĂŞtre modifiĂŠe pour reflĂŠter ainsi les nouvelles adresses virtuelles.
Mapper des pages de 4 Mo pour le noyau est simple, mais gaspille de la mÊmoire (sauf si vous avez vraiment un gros noyau). La crÊation d'un noyau de la moitiÊ supÊrieure mappÊ en tant que pages de 4 ko Êconomise de la mÊmoire, mais est plus difficile à mettre en place. La mÊmoire pour le rÊpertoire de page et une table de page peut être rÊservÊe dans la section .data, mais on a besoin de configurer le mappage des adresses virtuelles vers des adresses physiques au moment de l'exÊcution. La taille du noyau peut être dÊterminÊe par l'exportation d'Êtiquettes à partir du script d'Êdition de liens (37), que nous devons faire de toute façon plus tard, lors de l'Êcriture de l'allocateur de trame de page (voir le chapitre Allocation de trames de pageAllocation de trames de page).
9-4. MĂŠmoire virtuelle via pagination▲
La pagination permet deux choses qui sont bonnes pour la mÊmoire virtuelle. Tout d'abord, elle permet un contrôle à granulation fine de l'accès à la mÊmoire. Vous pouvez marquer les pages en lecture seule, lecture et Êcriture, seulement pour PL0, etc. Deuxièmement, il crÊe l'illusion d'une mÊmoire contiguÍ. Les processus en mode utilisateur et le noyau peuvent accÊder à la mÊmoire comme si elle Êtait contiguÍ et la mÊmoire contiguÍ peut être Êtendue sans avoir besoin de dÊplacer des donnÊes en mÊmoire. Nous pouvons Êgalement permettre aux programmes en mode utilisateur d'accÊder à toute la mÊmoire en dessous de 3 Go, mais à moins qu'ils l'utilisent rÊellement, nous ne devons pas assigner des trames de page aux pages. Cela permet aux processus d'avoir le code situÊ près de 0x00000000 et la pile à juste en dessous de 0xC0000000 et de n'avoir toujours pas besoin de plus de deux pages rÊelles.
9-5. Lectures complĂŠmentaires▲
- Le chapitre 4 (et dans une certaine mesure le chapitre 3) du manuel Intel (33) sont vos sources dĂŠfinitives pour les dĂŠtails sur la pagination.
- WikipÊdia fournit un article sur la pagination : http://en.wikipedia.org/wiki/Paging,
 https://fr.wikipedia.org/wiki/MĂŠmoire_virtuelle#M.C3.A9moire_virtuelle_pagin.C3.A9e.
https://fr.wikipedia.org/wiki/MÊmoire_virtuelle#M.C3.A9moire_virtuelle_pagin.C3.A9e. - Le wiki de OSDev contient une page au sujet de la pagination : http://wiki.osdev.org/Paging et un tutoriel pour faire un noyau de moitiÊ supÊrieure : http://wiki.osdev.org/Higher_Half_bare_bones.
- L'article de Gustavo Duarte sur la façon dont un noyau gère la mÊmoire mÊrite bien une lecture : http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory.
- Des dĂŠtails sur le langage de commande de l'ĂŠditeur des liens peuvent ĂŞtre trouvĂŠs sur le site de Steve Chamberlain (37).
- Plus de dÊtails sur le format ELF peuvent être trouvÊs dans cette prÊsentation : http://flint.cs.yale.edu/cs422/doc/ELF_Format.pdf.
10. Allocation de trames de page▲
Lors de l'utilisation de la mÊmoire virtuelle, comment l'OS sait-il quelles parties de la mÊmoire peuvent être utilisÊes ? Tel est le rôle de l'allocateur de trame de page.
10-1. GĂŠrer la mĂŠmoire disponible▲
10-1-1. Combien de mĂŠmoire se trouve lĂ Â ?▲
Nous devons d'abord savoir combien de mÊmoire est disponible sur l'ordinateur sur lequel l'OS est exÊcutÊ. La meilleure façon d'y arriver est de le lire à partir de la structure multiamorce (19) que GRUB nous passe. GRUB recueille les informations sur la mÊmoire dont nous avons besoin - ce qui est rÊservÊ, mappÊ en E/S, en lecture seule, etc. Nous devons Êgalement nous assurer que nous ne marquons pas comme disponible la partie de la mÊmoire utilisÊe par le noyau (puisque GRUB ne marque pas cette mÊmoire comme rÊservÊe). Une façon de savoir combien de mÊmoire utilise le noyau est d'exporter des Êtiquettes du dÊbut et de la fin du binaire du noyau à partir du script d'Êditeur de liens :
ENTRY(loader) /* le nom du symbole en entrĂŠe */
. = 0xC0100000 /* le code doit ĂŞtre relocalisĂŠ Ă 3 Go + 1 Mo */
/* ces ĂŠtiquettes seront exportĂŠes dans les fichiers de code */
kernel_virtual_start = .;
kernel_physical_start = . - 0xC0000000;
/* alignement Ă 4 ko et chargement Ă 1 Mo */
.text ALIGN (0x1000) : AT(ADDR(.text)-0xC0000000)
{
*(.text) /* toutes les sections texte, de tous les fichiers */
}
/* alignement Ă 4 ko et chargement Ă 1 Mo + . */
.rodata ALIGN (0x1000) : AT(ADDR(.rodata)-0xC0000000)
{
*(.rodata*) /* toutes les sections de donnĂŠes en lecture seule, de tous les fichiers */
}
/* alignement Ă 4 ko et chargement Ă 1 Mo + . */
.data ALIGN (0x1000) : AT(ADDR(.data)-0xC0000000)
{
*(.data) /* toutes les sections de donnĂŠes, de tous les fichiers */
}
/* alignement Ă 4 ko et chargement Ă 1 MB + . */
.bss ALIGN (0x1000) : AT(ADDR(.bss)-0xC0000000)
{
*(COMMON) /* toutes les sections COMMON, de tous les fichiers */
*(.bss) /* toutes les sections bss, de tous les fichiers */
}
kernel_virtual_end = .;
kernel_physical_end = . - 0xC0000000;Ces ĂŠtiquettes peuvent ĂŞtre lues directement Ă partir du code assembleur et dĂŠposĂŠes sur la pile pour les mettre Ă la disposition du code CÂ :
extern kernel_virtual_start
extern kernel_virtual_end
extern kernel_physical_start
extern kernel_physical_end
; ...
push kernel_physical_end
push kernel_physical_start
push kernel_virtual_end
push kernel_virtual_start
call kmainDe cette façon, nous obtenons les Êtiquettes comme arguments à kmain. Si vous souhaitez utiliser du C au lieu de l'assembleur, une façon de faire est de dÊclarer les Êtiquettes comme des fonctions et de prendre les adresses de ces fonctions :
void kernel_virtual_start(void);
/* ... */
unsigned int vaddr = (unsigned int) &kernel_virtual_start;Si vous utilisez des modules GRUB, vous devez vous assurer que la mĂŠmoire qu'ils utilisent est aussi marquĂŠe comme rĂŠservĂŠe.
Notez que la mĂŠmoire disponible n'a pas besoin d'ĂŞtre contiguĂŤ. Dans le premier 1 Mo il y a plusieurs sections d'E/S mappĂŠes en mĂŠmoire, aussi que de la mĂŠmoire utilisĂŠe par GRUB et le BIOS. D'autres parties de la mĂŠmoire pourraient ĂŞtre tout aussi indisponibles.
Il est commode de diviser les sections de mÊmoire en trames de pages complètes, car nous ne pouvons pas mapper en mÊmoire des parties de pages.
10-1-2. GĂŠrer la mĂŠmoire disponible▲
Comment savons-nous quelles trames de page sont en cours d'utilisation ? L'allocateur de trame de page doit garder une trace des trames libres et de celles qui ne le sont pas. Il y a plusieurs façons de faire cela : les bitmaps, les listes chaÎnÊes, les arbres, le Buddy System (utilisÊ par Linux), etc. Pour plus d'informations sur les diffÊrents algorithmes, voir l'article sur OSDev(37).
Les bitmaps sont assez faciles Ă mettre en Ĺuvre. Un bit est utilisĂŠ pour chaque trame de page et une (ou plusieurs) trame de pages est consacrĂŠe Ă stocker le bitmap. (Notez que ceci est juste une façon de le faire, d'autres dispositifs pourraient ĂŞtre meilleurs et/ou plus amusants Ă mettre en Ĺuvre.)
10-2. Comment pouvons-nous accĂŠder Ă une trame de page ?▲
Nous devons mapper la trame de page dans la mÊmoire virtuelle en mettant à jour la PDT et/ou la PT utilisÊe par le noyau. Que se passe-t-il si toutes les tables de pages disponibles sont pleines ? Dans ce cas-là , nous ne pouvons pas mapper la trame de page en mÊmoire, parce que nous aurions besoin d'une nouvelle table de page - qui occupe toute une trame de page - et pour Êcrire dans cette trame de page, nous devrions mapper sa trame de page... Il faut rompre d'une façon ou d'une autre ce cercle vicieux.
Une solution consiste à rÊserver une partie de la première table de page utilisÊe par le noyau (ou une autre table de page de la moitiÊ supÊrieure) pour mapper temporairement les trames de page afin de les rendre accessibles. Si le noyau est mappÊ à 0xC0000000 (enregistrement du rÊpertoire de page avec l'indice 768), et 4 ko de trames de page sont utilisÊs, alors le noyau a au moins une table de page. Si nous supposons - ou nous limitons à - un noyau de taille d'au plus 4 Mo moins 4 ko, nous pouvons consacrer le dernier enregistrement (enregistrement 1023) de cette table de page pour mappages temporaires. L'adresse virtuelle des pages mappÊes en utilisant le dernier enregistrement de la PT du noyau sera :
(768 << 22) | (1023 << 12) | 0x000 = 0xC03FF000Après avoir mappÊ temporairement la trame de page que nous voulons utiliser comme table de page et l'avoir configurÊe pour mapper vers notre première trame de page, nous pouvons l'ajouter au rÊpertoire de pagination et supprimer le mappage temporaire.
10-3. Un tas du noyau▲
Jusqu'Ă prĂŠsent, nous avons ĂŠtĂŠ en mesure de travailler seulement avec des donnĂŠes de taille fixe, ou directement avec de la mĂŠmoire brute. Maintenant que nous avons un allocateur de trame de page, nous pouvons mettre en Ĺuvre des fonctions malloc et free pour les utiliser dans le noyau.
Kernighan et Ritchie donnent dans leur livre (8)un exemple d'implĂŠmentation dont nous pouvons nous inspirer. La seule modification que nous devons faire est de remplacer les appels Ă sbrk/brk par des appels Ă l'allocateur de trame de page lorsque plus de mĂŠmoire est nĂŠcessaire. Nous devons ĂŠgalement veiller Ă mapper vers des adresses virtuelles les trames de page renvoyĂŠes par l'allocateur. Une mise en Ĺuvre correcte doit ĂŠgalement retourner des trames de page Ă l'allocateur lors d'appels Ă la fonction free, chaque fois que des blocs de mĂŠmoire suffisamment de grands sont libĂŠrĂŠs.
10-4. Lecture complĂŠmentaire▲
- La page OSDev wiki sur l'allocation de trame de page : http://wiki.osdev.org/Page_Frame_Allocation.
11. Mode utilisateur▲
Le mode utilisateur est maintenant presque Ă notre portĂŠe, il reste juste encore quelques mesures nĂŠcessaires pour y arriver. Bien que ces mesures puissent sembler faciles comme elles sont prĂŠsentĂŠes dans ce chapitre, leur mise en Ĺuvre peut s'avĂŠrer dĂŠlicate, car il y a beaucoup de cas oĂš de petites erreurs provoqueront des bogues difficiles Ă trouver.
11-1. Segments pour le mode utilisateur▲
Pour activer le mode utilisateur, nous devons ajouter deux segments supplÊmentaires à la GDT. Ceux-ci sont très semblables aux segments du noyau que nous avons ajoutÊs lorsque nous avons configurÊ la GDTLa table de descripteurs globaux (GDT), dans le chapitre sur la segmentationSegmentation :
|
Index |
Offset |
Nom |
Plage d'adressage |
Type |
DPL |
|---|---|---|---|---|---|
|
3 |
0x18 |
segment de code utilisateur |
0x00000000 - 0xFFFFFFFF |
RX |
PL3 |
|
4 |
0x20 |
segment de donnĂŠes utilisateur |
0x00000000 - 0xFFFFFFFF |
RW |
PL3 |
Les descripteurs de segment nĂŠcessaires pour le mode utilisateur
La diffÊrence est le DPL, qui permet maintenant l'exÊcution du code en niveau de privilège PL3. Les segments peuvent toujours être utilisÊs pour accÊder à tout l'espace d'adresses, ce qui veut dire que l'utilisation de ces segments pour le code en mode utilisateur ne protÊgera pas le noyau. Pour cela, nous avons besoin de pagination.
11-2. Configurer le mode utilisateur▲
Il y a quelques petites choses dont chaque processus en mode utilisateur a besoin :
- des trames de page pour le code, les donnĂŠes et la pile. Pour le moment, il suffit d'allouer une trame de page pour la pile et suffisamment de trames de page pour contenir le code du programme. Pour l'instant, ne vous prĂŠoccupez pas de la mise en place d'une pile qui peut grandir et rĂŠtrĂŠcir, concentrez-vous d'abord sur l'obtention d'une mise en Ĺuvre simple ;
- le binaire du module GRUB doit être copiÊ dans les trames de page utilisÊes pour le code des programmes ;
- un rÊpertoire de pages et des tables de pages sont nÊcessaires pour mapper en mÊmoire les trames de page dÊcrites ci-dessus. Au moins deux tables de pages sont nÊcessaires, parce que le code et les donnÊes doivent être mappÊs au 0x00000000 et augmenter, et la pile doit commencer juste en dessous du noyau, à 0xBFFFFFFB et croÎtre vers des adresses infÊrieures. Le drapeau U/S doit être configurÊ pour permettre l'accès PL3.
Il pourrait ĂŞtre pratique de stocker ces informations dans une struct reprĂŠsentant un processus. Cette struct de processus peut ĂŞtre allouĂŠe dynamiquement avec la fonction malloc du noyau.
11-3. Entrer en mode utilisateur▲
La seule façon d'exÊcuter du code avec un niveau de privilège infÊrieur au niveau de privilège courant (current privilege level - CPL) est d'exÊcuter une instruction iret ou lret - retour ou long retour après interruption, respectivement.
Pour entrer en mode utilisateur, nous mettons en place la pile comme si le processeur avait lancÊ une interruption de niveau inter-privilège. La pile doit ressembler à ce qui suit :
[esp + 16] ss ; le sĂŠlecteur de segment de pile que nous voulons pour le mode utilisateur
[esp + 12] esp ; le pointeur de pile en mode utilisateur
[esp + 8] eflags ; les options de contrĂ´le que nous voulons utiliser en mode utilisateur
[esp + 4] cs ; le sĂŠlecteur de segment de code
[esp + 0] eip ; le pointeur d'instruction du code du mode utilisateur Ă exĂŠcuterVoir le manuel Intel (33), section 6.2.1, figure 6-4 pour plus d'informations.
L'instruction iret lira alors ces valeurs de la pile et remplira les registres correspondants. Avant d'exÊcuter iret, nous devons changer de rÊpertoire vers celui configurÊ pour le processus en mode utilisateur. Il est important de rappeler que pour poursuivre l'exÊcution de code du noyau après avoir changÊ de PDT, le noyau doit être mappÊ. Une façon d'accomplir cela est d'avoir une PDT sÊparÊe pour le noyau, qui mappe toutes les donnÊes à 0xC0000000 et au-dessus, et la fusionner avec la PDT de l'utilisateur (qui ne mappe qu'en dessous de 0xC0000000) lors de l'exÊcution du changement de rÊpertoire. Rappelez-vous que l'adresse physique de la PDT doit être utilisÊe lors de la configuration du registre cr3.
Le registre eflags contient un ensemble d'indicateurs diffÊrents, spÊcifiÊs dans la section 2.3 du manuel Intel (33). Le plus important pour nous est celui d'activation d'interruption (interrupt enable flag - IF). L'instruction assembleur sti ne peut pas être utilisÊe pour activer les interruptions au niveau de privilège 3. Si les interruptions sont dÊsactivÊes en entrant en mode utilisateur, elles ne peuvent plus être activÊes une fois en mode utilisateur. Le placement de l'indicateur IF sur la pile, dans l'entrÊe eflags, activera les interruptions en mode utilisateur, puisque l'instruction en assembleur iret configurera le registre eflags à la valeur correspondante sur la pile.
Pour l'instant, nous devrions avoir dÊsactivÊ les interruptions, car il faut un peu plus de travail pour faire fonctionner correctement les interruptions de niveau interprivilège (voir la section Appels systèmeAppels système).
La valeur eip sur la pile doit pointer vers le point d'entrĂŠe du code utilisateur - 0x00000000 dans notre cas. La valeur esp sur la pile doit ĂŞtre lĂ oĂš la pile commence - 0xBFFFFFFB (0xC0000000 - 4).
Les valeurs cs et ss sur la pile doivent être les sÊlecteurs de segment pour les segments de code et respectivement de donnÊes de l'utilisateur. Comme nous l'avons vu dans le chapitre sur la segmentationSegmentation, les deux bits infÊrieurs d'un sÊlecteur de segment dÊfinissent le RPL - le niveau de privilège requis. Lors de l'utilisation de iret pour entrer en PL3, le RPL de cs et ss doit être 0x3. Le code suivant montre un exemple :
USER_MODE_CODE_SEGMENT_SELECTOR equ 0x18
USER_MODE_DATA_SEGMENT_SELECTOR equ 0x20
mov cs, USER_MODE_CODE_SEGMENT_SELECTOR | 0x3
mov ss, USER_MODE_DATA_SEGMENT_SELECTOR | 0x3Le registre ds et les autres registres de segments de donnÊes doivent être configurÊs sur le même sÊlecteur de segment que ss. Ils peuvent être dÊfinis de la façon habituelle, avec l'instruction assembleur mov.
Nous sommes maintenant prĂŞts Ă exĂŠcuter iret. Si tout a ĂŠtĂŠ mis en place correctement, nous devrions maintenant avoir un noyau qui peut entrer en mode utilisateur.
11-4. Utiliser le C pour les programmes en mode utilisateur▲
Lorsque le C est utilisĂŠ comme langage de programmation pour les programmes en mode utilisateur, il est important de rĂŠflĂŠchir Ă la structure du fichier qui rĂŠsultera de la compilation.
La raison pour laquelle nous pouvons utiliser ELF (18) comme format de fichier pour l'exĂŠcutable du noyau est parce que GRUB sait comment analyser et interprĂŠter le format de fichier ELF. Si nous avions mis en Ĺuvre un analyseur de ELF, nous pourrions aussi compiler les programmes en mode utilisateur en binaires ELF. Nous laissons cela comme un exercice pour le lecteur.
Pour faciliter le dÊveloppement des programmes en mode utilisateur, nous pouvons permettre aux programmes d'être Êcrits en C, mais les compiler en binaires plats au lieu de binaires ELF. En C, la mise en page du code gÊnÊrÊ est plus imprÊvisible et le point d'entrÊe, main, pourrait ne pas être à l'offset 0 dans le binaire. Une façon courante de contourner cela est d'ajouter quelques lignes de code assembleur placÊes à l'offset 0, qui appellent main :
extern main
section .text
; push argv
; push argc
call main
; main a retournĂŠ, eax est la valeur de retour
jmp $ ; boucle infinieSi ce code est enregistrĂŠ dans un fichier appelĂŠ start.s, alors le code suivant montre un exemple de script d'ĂŠdition de liens qui place ces instructions d'abord en exĂŠcutable (rappelez-vous que start.s est compilĂŠ en start.o)Â :
OUTPUT_FORMAT("binary") /* output binaire plat */
SECTIONS
{
. = 0; /* relocaliser Ă l'adresse 0 */
.text ALIGN(4):
{
start.o(.text) /* inclure la section .text de start.o */
*(.text) /* inclure les autres sections .text */
}
.data ALIGN(4):
{
*(.data)
}
.rodata ALIGN(4):
{
*(.rodata*)
}
}Remarque : *(.text) n'inclura pas encore une fois la section .text de start.o.
Avec ce script, nous pouvons ĂŠcrire des programmes en C ou assembleur (ou tout autre langage qui compile en fichiers objet pouvant ĂŞtre liĂŠs avec ld), et le noyau les chargera et mappera facilement (cependant , .rodata sera mappĂŠ comme ĂŠtant en ĂŠcriture).
Lorsque nous compilons des programmes utilisateur, nous voulons les options GCC suivantes :
-m32 -nostdlib -nostdinc -fno-builtin -fno-stack-protector
-nostartfiles -nodefaultlibsPour l'Êdition des liens, les options suivantes doivent être utilisÊes :
-T link.ld -melf_i386 # ĂŠmuler ELF 32 bits, la sortie binaire est spĂŠcifiĂŠe
# dans le script d'ĂŠdition de liensL'option -T indique Ă l'ĂŠditeur de liens d'utiliser le script d'ĂŠdition de liens link.ld.
11-4-1. Une bibliothèque C▲
à ce stade, il pourrait être intÊressant de commencer à penser à Êcrire une petite  bibliothèque standard  pour vos programmes. Certaines fonctionnalitÊs nÊcessitent des appels systèmeAppels système pour fonctionner, mais certaines, comme les fonctions dÊclarÊes dans string.h, n'en ont pas besoin.
11-5. Lecture complĂŠmentaire▲
- Gustavo Duarte a un article sur les niveaux de privilèges : http://duartes.org/gustavo/blog/post/cpu-rings-privilege-and-protection.
12. Systèmes de fichiers▲
Il n'est pas indispensable d'avoir des systèmes de fichiers dans notre système d'exploitation, mais c'est une abstraction très utile, et cela joue souvent un rĂ´le central de nombreux systèmes d'exploitation, en particulier les systèmes d'exploitation de type UNIX. Avant de commencer Ă mettre en place les ĂŠlĂŠments nĂŠcessaires aux processus multiples et aux appels système, nous pourrions envisager de mettre en Ĺuvre un système de fichiers simple.
12-1. Pourquoi un système de fichiers ?▲
Comment pouvons-nous prÊciser quels programmes exÊcuter dans notre OS ? Quel est le premier programme à exÊcuter ? Comment les programmes font-ils pour produire des donnÊes ou en lire en entrÊe ?
Dans les systèmes de type UNIX, qui ont pour convention que presque tout est un fichier, ces problèmes sont rÊsolus par le système de fichiers. (Il pourrait Êgalement être intÊressant à lire un peu sur le projet Plan 9 de Bell Labs, qui pousse l'idÊe du  tout fichier  un cran plus loin.)
12-2. Un système de fichiers simple, en lecture seule▲
Le système de fichiers le plus simple pourrait être ce que nous avons dÊjà - un seul fichier, existant uniquement dans la RAM, chargÊ par GRUB avant le dÊmarrage du noyau. Lorsque le noyau et le système d'exploitation croissent, cela devient probablement trop limitatif.
Un fichier avec des mÊtadonnÊes est un système de fichiers lÊgèrement plus avancÊ que celui reprÊsentÊ seulement par les bits d'un seul fichier. Les mÊtadonnÊes peuvent dÊcrire le type du fichier, sa taille et ainsi de suite. Un programme utilitaire qui s'exÊcute à la compilation peut être crÊÊ en ajoutant ces mÊtadonnÊes dans un fichier. De cette façon, un  système de fichiers dans un fichier  peut être construit par la concatÊnation de plusieurs fichiers avec des mÊtadonnÊes dans un grand fichier. Le rÊsultat de cette technique est un système de fichiers en lecture seule qui rÊside dans la mÊmoire (une fois que GRUB a chargÊ le fichier).
Le programme qui construit le système de fichiers peut traverser un rÊpertoire sur le système hôte et ajouter tous les sous-rÊpertoires et les fichiers dans le cadre du système de fichiers cible. Chaque objet dans le système de fichiers (rÊpertoire ou fichier) peut consister en un en-tête et un corps, oÚ le corps d'un fichier est le fichier même et le corps d'un rÊpertoire est une liste d'entrÊes - noms et  adresses  d'autres fichiers et rÊpertoires.
Les objets dans ce système de fichiers deviendront contigus, donc le noyau les lira facilement dans la mÊmoire. Tous les objets auront Êgalement une taille fixe (à l'exception du dernier, qui peut augmenter), il est donc difficile d'ajouter de nouveaux fichiers ou de modifier ceux qui existent.
12-3. NĹuds d'index (inodes) et systèmes de fichiers accessibles en ĂŠcriture▲
Lorsque l'on envisage un système de fichiers accessible en ĂŠcriture, c'est une bonne idĂŠe de se pencher sur le concept d'un nĹud d'index ou inode. Voir la section Lectures complĂŠmentairesLectures complĂŠmentaires pour des lectures recommandĂŠes.
12-4. Un système virtuel de fichiers▲
Quelle abstraction utiliser pour la lecture et l'Êcriture sur les dispositifs tels que l'Êcran et le clavier ?
Un système virtuel de fichiers (VFS) crÊe une abstraction au-dessus des systèmes de fichiers concrets. Un VFS fournit principalement le système de chemins et une hiÊrarchie de fichiers, il dÊlègue les opÊrations sur les fichiers aux systèmes de fichiers sous-jacents. Le document original sur les VFS est succinct et mÊrite bien une lecture. Voir la section Lectures complÊmentairesLectures complÊmentaires pour une rÊfÊrence.
Avec un VFS, nous pourrions monter un système de fichiers spÊcial sur le chemin /dev. Ce système de fichiers gÊrerait tous les pÊriphÊriques tels que les claviers et la console. Cependant, on pourrait aussi suivre l'approche traditionnelle UNIX, avec numÊros majeurs/mineurs de pÊriphÊriques et mknod pour crÊer des fichiers spÊciaux pour ces pÊriphÊriques. C'est à vous de choisir l'approche que vous pensez être la plus adaptÊe, il n'y a pas de chose juste ni de chose incorrecte lors de la construction des couches d'abstraction (bien que certaines abstractions se rÊvèlent beaucoup plus utiles que d'autres).
12-5. Lectures complĂŠmentaires▲
- Les idĂŠes derrière les systèmes d'exploitation Plan 9 valent la peine d'y jeter un coup d'Ĺil : http://plan9.bell-labs.com/plan9/index.html
- La page de WikipĂŠdia sur les nĹuds d'index : https://fr.wikipedia.org/wiki/NĹud_d'index et la structure de pointeur de nĹud d'index : http://en.wikipedia.org/wiki/Inode_pointer_structure
- Le document original sur le concept de vnodes et de système de fichiers virtuel est assez intÊressant : https://cgi.cse.unsw.edu.au/~cs3231/15s1/assignments/asst2/kleiman86vnodes.pdf (NdT)
- Poul-Henning Kamp discute de l'idÊe d'un système de fichiers spÊcial pour /dev dans http://static.usenix.org/publications/library/proceedings/bsdcon02/full_papers/kamp/kamp_html/index.html
13. Appels système▲
Les appels système sont le mÊcanisme par lequel les applications en mode utilisateur interagissent avec le noyau - pour solliciter des ressources ou demander que des opÊrations soient effectuÊes, etc. L'API des appels système est la partie du noyau la plus visible aux yeux des utilisateurs, donc sa conception nÊcessite une certaine rÊflexion.
13-1. Concevoir des appels système▲
C'est à nous, les dÊveloppeurs du noyau, de concevoir les appels système que les dÊveloppeurs d'applications peuvent utiliser. Nous pouvons nous inspirer des normes POSIX ou, si elles semblent trop de travail, il suffit de regarder ceux pour Linux et de choisir. Voir la section Lecture complÊmentaireLecture complÊmentaire à la fin du chapitre 10 pour rÊfÊrences.
13-2. ImplĂŠmenter les appels système▲
Les appels système sont traditionnellement invoquÊs avec des interruptions logicielles. Les applications de l'utilisateur mettent les valeurs appropriÊes dans les registres ou sur la pile puis dÊclenchent une interruption prÊdÊfinie, qui transfère l'exÊcution au noyau. Le numÊro d'interruption utilisÊ dÊpend du noyau, Linux utilise le numÊro 0x80 pour identifier une interruption destinÊe à dÊclencher un appel système.
Lors de l'exÊcution des appels système, le niveau de privilège actuel passe gÊnÊralement de PL3 à PL0 (si l'application s'exÊcute en mode utilisateur). Il faut donc que le DPL de l'enregistrement de l'IDT correspondant à l'interruption d'appel système permette l'accès PL3.
Chaque fois que des interruptions impliquant un changement de niveau de privilège se produisent, le processeur dÊpose quelques registres importants sur la pile - les mêmes que nous avons utilisÊs prÊcÊdemment pour entrer en mode utilisateur ; voir la figure 6-4, section 6.12.1, dans le manuel Intel (33). Quelle pile utiliser ? La même section dans le manuel Intel prÊcise que si une interruption conduit à l'exÊcution de code ayant un niveau de privilège numÊriquement plus faible, un changement de pile se produit. Les nouvelles valeurs pour les registres ss et esp sont chargÊes à partir du segment d'Êtat de tâche (TSS) courant. La structure du TSS est spÊcifiÊe dans la figure 7-2, la section 7.2.1 du manuel Intel.
Pour activer les appels système, nous devons mettre en place un TSS avant d'entrer en mode utilisateur. Sa mise en place peut être faite en C, en dÊfinissant les champs ss0 et esp0 d'une  struct compactÊe  qui reprÊsente un TSS. Avant de charger la  struct compactÊe  dans le processeur, un descripteur TSS doit être ajoutÊ à la GDT. La structure du descripteur TSS est dÊcrite dans la section 7.2.2 du manuel Intel.
Vous spĂŠcifiez le sĂŠlecteur de segment TSS courant en le chargeant dans le registre tr avec l'instruction assembleur ltr. Si le descripteur de segment TSS a l'index 5, et ainsi le dĂŠcalage est 5 * 8 = 40 = 0x28, celle-ci est la valeur qui doit ĂŞtre chargĂŠe dans le registre tr.
Lorsque nous sommes entrĂŠs en mode utilisateur dans le chapitre Entrer en mode utilisateurEntrer en mode utilisateur, nous avons dĂŠsactivĂŠ les interruptions lors de l'exĂŠcution en PL3. Puisque les appels système sont mis en Ĺuvre en utilisant les interruptions, les interruptions doivent ĂŞtre activĂŠes en mode utilisateur. En dĂŠfinissant le bit indicateur IF Ă la valeur eflags sur la pile, nous ferons en sorte que iret active les interruptions (puisque la valeur eflags sur la pile sera chargĂŠe dans le registre eflags par l'instruction assembleur iret).
13-3. Lectures complĂŠmentaires▲
- La page WikipÊdia sur POSIX, avec des liens vers les spÊcifications : https://fr.wikipedia.org/wiki/POSIX
- Une liste des appels système utilisÊs dans Linux : http://bluemaster.iu.hio.no/edu/dark/lin-asm/syscalls.html
- La page WikipÊdia sur l'appel système : https://fr.wikipedia.org/wiki/Appel_système
- Les sections du manuel Intel (33) sur les interruptions (chapitre 6) et TSS (chapitre 7) sont la source de rĂŠfĂŠrence oĂš vous obtiendrez tous les dĂŠtails dont vous avez besoin.
14. Multitâche▲
Comment faire pour que de multiples processus semblent fonctionner en même temps ? Aujourd'hui, cette question a deux rÊponses :
- avec la disponibilitĂŠ de processeurs multicĹurs ou de systèmes avec de multiples processeurs, deux processus peuvent effectivement s'exĂŠcuter en mĂŞme temps, en les exĂŠcutant sur des cĹurs ou des processeurs diffĂŠrents ;
- simuler, c'est-à -dire commuter rapidement (plus vite qu'un humain ne peut s'en apercevoir) entre processus. à tout moment donnÊ, il y a un seul processus en exÊcution, mais la commutation rapide donne l'impression qu'ils s'exÊcutent  en même temps .
Puisque le système d'exploitation crĂŠĂŠ dans ce livre ne supporte pas les processeurs multicĹurs ou plusieurs processeurs, la seule option est de simuler. La partie du système d'exploitation responsable de commuter rapidement entre les processus est appelĂŠe l'algorithme d'ordonnancement.
14-1. CrĂŠer de nouveaux processus▲
La crĂŠation de nouveaux processus est gĂŠnĂŠralement faite par deux appels système diffĂŠrents : fork et exec. fork crĂŠe une copie exacte du processus en cours d'exĂŠcution, tandis qu'exec remplace le processus courant avec celui spĂŠcifiĂŠ par un chemin d'accès Ă l'emplacement d'un programme dans le système de fichiers. Entre ces deux options, nous vous recommandons de commencer par la mise en Ĺuvre d'exec, puisque cet appel système va suivre presque exactement les mĂŞmes ĂŠtapes que celles dĂŠcrites dans la section Configurer le mode utilisateurConfigurer le mode utilisateur du chapitre Mode utilisateurMode utilisateur.
14-2. Ordonnancement en mode multitâche coopĂŠratif▲
La façon la plus facile d'effectuer une commutation rapide entre processus est de rendre les processus eux-mêmes responsables de la commutation. Les processus sont exÊcutÊs pendant un certain temps, puis disent au système d'exploitation (via un appel système) qu'il peut maintenant passer à un autre processus. Rendre le contrôle du CPU à l'autre processus s'appelle rendre la main et lorsque les processus eux-mêmes sont responsables de l'ordonnancement, on appelle cela le mode coopÊratif, puisque tous les processus doivent coopÊrer les uns avec les autres.
Quand un processus rend la main, tout l'ĂŠtat du processus doit ĂŞtre enregistrĂŠ (tous les registres), de prĂŠfĂŠrence sur le tas du noyau, dans une structure qui reprĂŠsente un processus. Lors du passage Ă un nouveau processus, tous les registres doivent ĂŞtre restaurĂŠs Ă partir des valeurs enregistrĂŠes.
L'ordonnancement peut ĂŞtre mis en Ĺuvre en gardant une liste des processus qui sont en cours d'exĂŠcution. L'appel système yield doit ensuite donner la main au processus suivant de la liste et mettre celui qui rend la main en dernier (d'autres mĂŠcanismes sont possibles, mais celui-ci est le plus simple).
Le transfert du contrôle au nouveau processus se fait via l'instruction assembleur iret, exactement de la même manière que cela a ÊtÊ fait dans la section Entrer en mode utilisateurEntrer en mode utilisateur du chapitre Mode utilisateurMode utilisateur.
Nous recommandons fortement que vous commenciez par mettre en Ĺuvre un mode multitâche coopĂŠratif. Nous recommandons en outre que vous ayez mis au point une solution fonctionnelle Ă la fois pour exec, fork et yield avant de vous lancer dans le mode multitâche prĂŠemptif. Comme le mode coopĂŠratif est dĂŠterministe, il est beaucoup plus facile Ă dĂŠboguer que le mode prĂŠemptif.
14-3. Ordonnancement en mode multitâche prĂŠemptif avec interruptions▲
Au lieu de laisser les processus dÊcider eux-mêmes quand rendre la main à un autre processus, l'OS peut commuter automatiquement les processus après une courte pÊriode de temps. Le système d'exploitation peut rÊgler la minuterie d'intervalle programmable (PIT) pour lancer une interruption après une courte pÊriode de temps, par exemple 20 millisecondes. Dans le gestionnaire d'interruptions pour l'interruption PIT, l'OS va remplacer le processus en cours par un autre. De cette façon, les processus eux-mêmes ne doivent pas se prÊoccuper de l'ordonnancement. Ce type d'ordonnancement est appelÊ mode prÊemptif.
14-3-1. Minuterie d'intervalle programmable (Programmable Interval Timer - PIT)▲
Pour ĂŞtre en mesure de faire de l'ordonnancement prĂŠemptif, la PIT doit d'abord ĂŞtre configurĂŠe pour dĂŠclencher des interruptions toutes les x millisecondes, oĂš x doit ĂŞtre un intervalle de temps configurable.
La configuration de la PIT est très similaire à la configuration des autres pÊriphÊriques matÊriels : un octet est envoyÊ sur un port d'E/S. Le port de commande de la PIT est 0x43. Pour connaÎtre toutes les options de configuration, veuillez consulter l'article sur la PIT sur OSDev(38). Nous utilisons les options suivantes :
- dĂŠclencher des interruptions (utiliser le canal 0)Â ;
- envoyer l'octet infĂŠrieur du diviseur, puis son octet supĂŠrieur (voir la section suivante pour une explication)Â ;
- utiliser une onde carrÊe ;
- utiliser le mode binaire.
Cela se traduit par l'octet de configuration 00110110.
La dÊfinition de l'intervalle de frÊquence à laquelle les interruptions doivent être levÊes se fait par l'intermÊdiaire d'un diviseur, de la même manière que pour le port sÊrie. Au lieu d'envoyer à la PIT une valeur (par exemple en millisecondes) qui prÊcise tous les combien une interruption doit être dÊclenchÊe, vous envoyez un diviseur. La PIT fonctionne par dÊfaut à 1 193 182 Hz. L'envoi du diviseur 10 a pour rÊsultat le fonctionnement de la PIT à 1193182/10 = 119318 Hz. Le diviseur ne peut être que sur 16 bits, il est donc possible de configurer la frÊquence de la minuterie entre 1 193 182 Hz et 1193182/65535 = 18,2 Hz. Nous vous recommandons de crÊer une fonction qui prend un intervalle en millisecondes et calcule le diviseur voulu.
Le diviseur est envoyĂŠ au port d'E/S de donnĂŠes du canal 0 de la PIT, mais comme on ne peut envoyer qu'un octet Ă la fois, les 8 bits infĂŠrieurs du diviseur doivent ĂŞtre envoyĂŠs en premier, puis les 8 bits les plus hauts du diviseur peuvent ĂŞtre envoyĂŠs. Le port d'E/S de donnĂŠes du canal 0 est situĂŠ Ă 0x40. Encore une fois, voir l'article sur OSDev (39) pour plus de dĂŠtails.
14-3-2. Piles sĂŠparĂŠes dans le noyau pour les processus▲
Si tous les processus utilisent la même pile noyau (la pile exposÊe par le TSS), il y aura des problèmes si un processus est interrompu lorsqu'il est encore en mode noyau. Le processus qui prend la main utilisera alors la même pile noyau et Êcrasera ce que le processus prÊcÊdent a Êcrit sur la pile (rappelez-vous que la structure de donnÊes TSS pointe vers le dÊbut de la pile).
Pour rÊsoudre ce problème, chaque processus doit avoir sa propre pile dans le noyau, tout comme chaque processus a sa propre pile en mode utilisateur. Lors de la commutation entre processus, le TSS doit être mis à jour pour pointer vers la pile noyau du nouveau processus.
14-3-3. DifficultĂŠs de l'ordonnancement prĂŠemptif▲
L'utilisation de l'ordonnancement prÊemptif pose un problème qui ne se pose pas avec l'ordonnancement coopÊratif. Avec l'ordonnancement coopÊratif, chaque fois qu'un processus rend la main, il est forcÊment en mode utilisateur (niveau de privilège 3), puisque rendre la main est un appel système. Avec l'ordonnancement prÊemptif, les processus peuvent être interrompus en mode utilisateur ou en mode noyau (niveau de privilège 0), puisque le processus lui-même ne contrôle pas quand il est interrompu.
L'interruption d'un processus en mode noyau est un peu diffÊrente de l'interruption d'un processus en mode utilisateur, en raison de la façon dont le processeur met en place la pile lors des interruptions. Si un changement de niveau de privilège a eu lieu (le processus a ÊtÊ interrompu en mode utilisateur), le processeur va dÊposer les valeurs des registres ss et esp du processus sur la pile. Si aucun changement de niveau de privilège ne se produit (le processus a ÊtÊ interrompu en mode noyau), le processeur ne dÊposera pas le registre esp sur la pile. En outre, si le niveau de privilège n'a pas changÊ, le processeur ne va pas basculer vers la pile dÊfinie dans le TSS.
Ce problème peut être rÊsolu en calculant la valeur de esp avant l'interruption. Puisque vous savez que le processeur dÊpose 3 choses sur la pile lorsqu'aucun changement de privilège ne se passe et vous savez combien vous en avez mis sur la pile, vous pouvez calculer la valeur de esp au moment de l'interruption. Ceci est possible, car le processeur ne va pas changer les piles s'il n'y a aucun changement de niveau de privilège, de sorte que le contenu de esp sera le même qu'au moment de l'interruption.
Pour compliquer encore les choses, il faut penser à la façon de traiter le cas lors du passage à un nouveau processus qui doit être exÊcutÊ en mode noyau. Puisque iret a ÊtÊ utilisÊ sans aucun niveau de privilège, le changement du CPU ne mettra pas à jour la valeur de esp avec celle qui est placÊe sur la pile - vous devez mettre à jour vous-même esp.
14-4. Lectures complĂŠmentaires▲
- Pour plus d'informations sur les diffĂŠrents algorithmes d'ordonnancement, voir http://wiki.osdev.org/Scheduling_Algorithms
15. Remerciements Developpez▲
Nous remercions Erik Helin et Adam Renberg pour la rĂŠdaction de ce tutoriel, le texte original peut ĂŞtre trouvĂŠ sur https://littleosbook.github.io/The little book about OS development. Nous remercions aussi Mishulyna pour sa traduction, lolo78 pour sa relecture technique ainsi que Claude Leloup pour sa relecture orthographique.
Les commentaires et les suggestions d'amÊlioration sont les bienvenus, alors, après votre lecture, n'hÊsitez pas.
9 commentaires ![]()
